

TL;DR
- Pattern dimension calculations in experiments are all about balancing error charges (Sort I & II).
- Use pattern dimension calculation formulation that match your take a look at design and assumptions (like equal variances or group sizes).
- You possibly can shrink the pattern dimension by selecting metrics with decrease variance or accepting a bigger MDE, however at all times guarantee your selections match your corporation actuality.
- At Optimizely, sample size estimation is tailor-made to the precise take a look at and metric, utilizing the delta technique for relative raise.
In the event you’ve ever tried planning pattern dimension for an experiment, you already know the web is stuffed with formulation. However not all formulation are created equal. Every comes with assumptions that will or could not match your take a look at and information actuality. And past these fundamentals, there are a couple of sensible nuances that may make or break your experiment’s success.
The origin of pattern dimension estimation (Error management for speculation take a look at) enhancement_commerce-analytics
Once you run a speculation take a look at in an experiment, you find yourself making certainly one of two choices: both reject the null speculation H0 or don’t reject it. However this determination could be incorrect because it’s based mostly on only one pattern from all the information you might have. In Frequentist speculation testing, we name these errors Typroduct_campaignpe I or Sort II errors, as proven within the desk under.
| Reject H0 | Not reject H0 | |
| H0 True | ✕ Sort I Error |
✓ |
| H1 True | ✓ | ✕ Sort II Error |
Normally, we consider a speculation take a look at by its chances of creating Sort I (α) and Sort II Errors (β). A great take a look at or experiment tries to maintain these chances low sufficient so we are able to belief the outcomes and make good choices based mostly on the experiment.
Any take a look at has a rule to determine when to reject H0. Normally, this rule checks if the noticed results fall inside a “rejection area” R. In the event that they do, we reject H0; if not, we don’t. If we outline the chance of rejecting H0 as Pr(noticed results ∈ R), this chance means various things relying on whether or not H0 or H1 is true.
- When H0 is true, Pr(noticed results ∈ R|H0 is true) = Pr(reject H0|H0 is true) = Sort I Error chance
- When H1 is true, Pr(noticed results ∈ R|H1 is true) = Pr(reject H0|H1 is true) = 1-Pr(not reject H0|H1 is true) = 1- Sort II Error chance
Put formally, we are able to outline the perform based mostly on θ (Casella & Berger, 2002):

Statisticians name this the “energy perform” as a result of 1 – Sort II Error chance is the chance of appropriately rejecting H0 when H1 is true— what we name the take a look at’s energy. This single perform combines details about a take a look at’s chance of creating each Sort I and Sort II Errors and thus is used to guage and evaluate totally different exams.
This is an instance: the graph under exhibits how the ability capabilities of two exams change relying on the true impact θ on the x-axis. To illustrate our speculation is H0: θ ≤ 0.5 versus H1: θ > 0.5. The perform β1(θ) tells us that take a look at 1 has a low chance of a Sort I Error when θ ≤ 0.5, but it surely has a excessive chance of a Sort II Error (i.e., low energy) when θ > 0.5. In distinction, β2(θ) exhibits that take a look at 2 has the next chance of a Sort I Error when θ ≤ 0.5, however a decrease chance of a Sort II Error (i.e., increased energy) when θ > 0.5. If it’s important to choose between these 2 exams, you have to determine which form of error sample—β1(θ) or β2(θ)—you discover extra acceptable.

Now, you may marvel what shapes the curve of β(θ) within the graph. It is dependent upon:
-
What sort of take a look at you choose
-
After choosing the take a look at sort, the way you set it up, such because the pattern dimension and/or Sort I/II Error threshold within the take a look at.
The Wald Take a look at dominates fixed-horizon Frequentist exams in trade A/B testing as a result of it’s computationally easy and extremely correct at giant scale (for detailed theoretical foundations of Wald sort exams, see Wu& Ding ,2021, Ding, 2024, Imbens & Rubin, 2015).
For 2-sided Wald Take a look at, the ability perform is roughly:
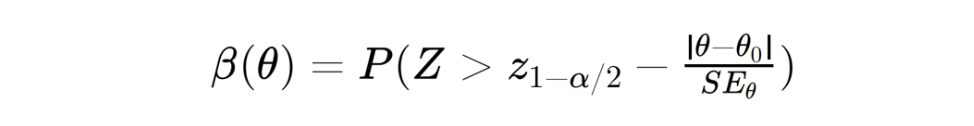 Then,
Then,
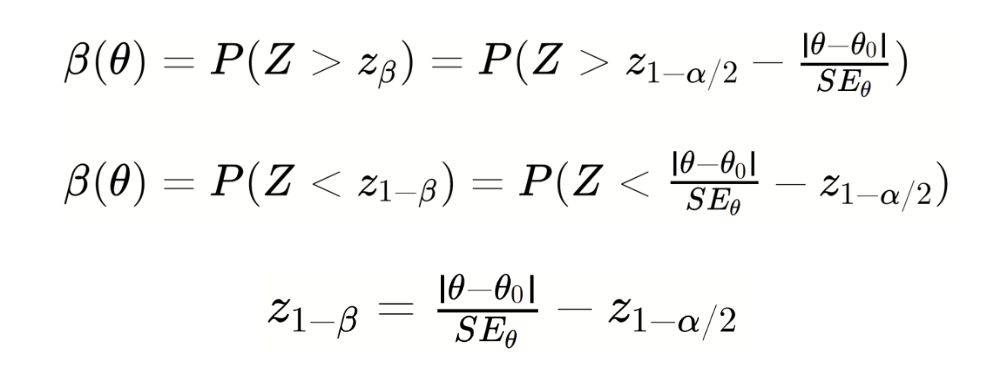 This final equation exhibits how folks give you totally different formulation for pattern dimension (for extra examples of pattern dimension estimation based mostly on energy capabilities, see e.g., Chow et al., 2017, Stuart et al., 2004, Casella & Berger, 2002, Davison, 2003, Cox & Hinkley, 1979). Particularly, adjustments relying on the assumptions you make.
This final equation exhibits how folks give you totally different formulation for pattern dimension (for extra examples of pattern dimension estimation based mostly on energy capabilities, see e.g., Chow et al., 2017, Stuart et al., 2004, Casella & Berger, 2002, Davison, 2003, Cox & Hinkley, 1979). Particularly, adjustments relying on the assumptions you make.
For instance, while you’re testing absolutely the imply distinction between two teams, a therapy group and a management group (which is the commonest setup in A/B testing), you may see totally different pattern dimension formulation. It is dependent upon assumptions like those within the desk under.
| Variance assumption | Pattern dimension assumption | SE0 | Per-group pattern dimension formulation |
| Equal variance | equal pattern dimension / unequal pattern dimension |
|

|
| Unequal variance | equal pattern dimension / unequal pattern dimension |

|

|
-
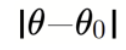 is set by your speculation. Particularly, it’s the minimal detectable impact (MDE) you have an interest in.
is set by your speculation. Particularly, it’s the minimal detectable impact (MDE) you have an interest in.
-
 have corresponding values when you determine on values of α and β
have corresponding values when you determine on values of α and β
A unique lens: Different paths that result in extra pattern dimension formulation
Belle (2011, pp. 27-29) defined how pattern dimension is calculated from a barely totally different angle.
Suppose we’re going to run a randomized experiment with a management group and a therapy group for testing a brand new characteristic. Formally, we specify the hypotheses as follows:
H0 (null speculation): No distinction between management and therapy teams.
H1 (different speculation): A distinction exists between management and therapy teams.
Additional, we assume the false constructive charge is alpha (sometimes 1%, 5%, or 10%), the false adverse charge is beta (normally 20%), and the imply distinction between the 2 teams is delta (e.g., minimal detectable impact; MDE). Determine 1 exhibits the sampling distributions below the null and different hypotheses. Beneath typical circumstances, the sampling distributions are roughly regular distributions when the pattern dimension is giant sufficient.
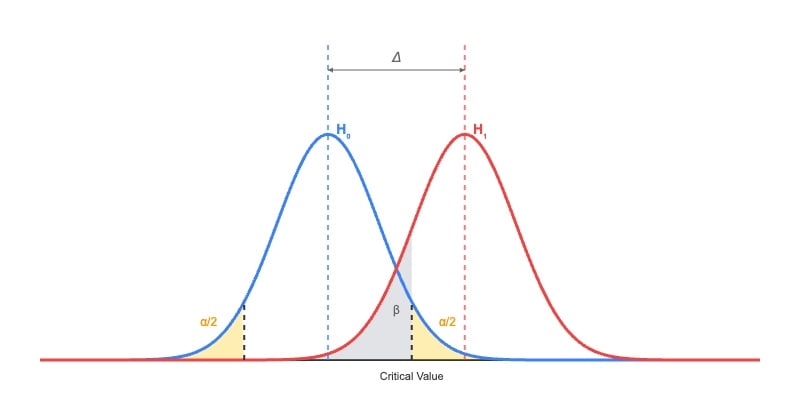 Picture: Sampling distributions
Picture: Sampling distributions
If the null speculation is true, then we’ve the next reality: Given alpha, the important worth (i.e., the boundary for not rejecting the null) should be equal to:
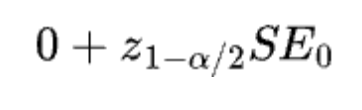 The place
The place
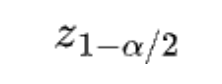 is the z-score at 100(1-alpha/2)th percentile and SE0 is the usual error below the null.
is the z-score at 100(1-alpha/2)th percentile and SE0 is the usual error below the null.
If the choice speculation is true, then we’ve the next reality: Given beta, the important worth (i.e., the boundary for rejecting the null) should be equal to:
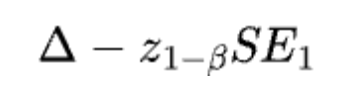 As a result of the important worth is for outlining the boundary for the rejection and the acceptance area, we should have
As a result of the important worth is for outlining the boundary for the rejection and the acceptance area, we should have

That is the final formulation that underlies pattern dimension estimation. At first look, it appears unrelated to pattern dimension, however normal errors rely upon pattern dimension and different components. Equally, you may as well get totally different pattern dimension choices utilizing this common formulation. For instance, for testing absolutely the imply distinction between a therapy group and a management group, you may give you totally different pattern dimension formulation based mostly on assumptions like those within the desk under.
To maintain it easy, we assume a z-test and equal pattern sizes n. You will discover formulation for unequal sizes by setting![]()
| Variance assumption | SE1 | SE0 | Per-group pattern dimension formulation |
| Equal variance |

|
Identical as SE1 |

|
| Unequal variance |

|
Identical as SE1 |

|
| Unequal variance |
|
Totally different from SE1
|

|


The easy “rule-of-thumb” formulation
Most pattern dimension formulation you see for on-line A/B testing come from the final formulation based mostly on these two frameworks above. For instance, let’s break down the well-known “rule-of-thumb” pattern dimension formulation ![]()
It’s typically usedin trade for a “fast estimation” of pattern dimension.
Let’s assume:
- The management and therapy teams are generated by regular distributions with the identical variance
- Equal visitors cut up, with every group having a pattern dimension of N.
Then common equation above turns into
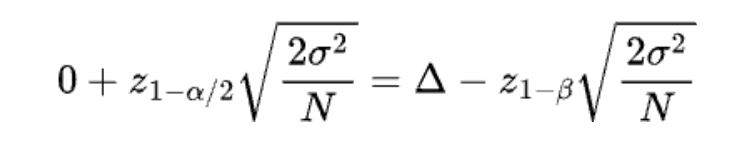 We are able to simply derive the pattern dimension N by fixing this equation
We are able to simply derive the pattern dimension N by fixing this equation
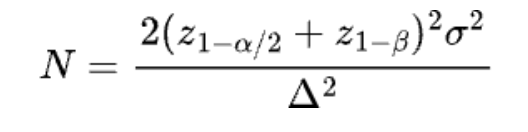 If α=0.05 and β=0.2, then
If α=0.05 and β=0.2, then
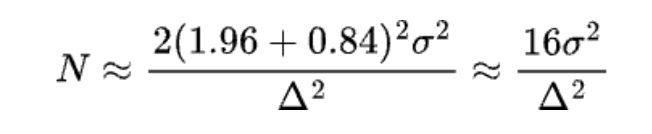
Finest practices for choosing a fundamental formulation:
Listed here are two backside strains about choosing pattern dimension formulation:
- Match the formulation to the take a look at: Your pattern dimension ought to match the statistical take a look at you intend to make use of. Every take a look at defines its personal important area and normal error, so your sample-size formulation ought to mirror these specifics.
- Know what assumptions you’re shopping for into: Each formulation makes some assumptions to maintain issues easy resembling equal group sizes, equal variances, large-sample normality, fixed variance throughout means, and so forth. All the time ask: Do these assumptions truly maintain in my experiment?
In brief:
The suitable formulation is the one which matches your take a look at design and data-generation actuality.
At Optimizely, we arrange a Wald take a look at (z-test) for our Fixed-horizon Frequentist test. We assume the teams have totally different pattern sizes and variances.Utilizing the ability perform framework, we choose the pattern dimension formulation proven under:

Pattern dimension estimation for relative enchancment and pattern dimension discount
Once you wish to take a look at relative enchancment.
The formulation above assist determine the pattern dimension wanted to check absolutely the imply distinction between two teams. Butin enterprise, folks normally like to speak about relative uplift as an alternative.
For instance, if the conversion charge is p0 = 0.1 and p1 = 0.15, absolutely the distinction is p1 – p0 = 0.05, whereas the relative distinction is (p1 – p0) / p0 = 0.5, or 50%.
There are two widespread methods to estimate the pattern dimension for testing relative variations between teams.
| Technique | Description | Binary metrics instance |
| Absolute-difference approximation |
Translate the relative raise into an absolute distinction.
Then, use the pattern dimension formulation for absolute distinction. |
|
| Delta technique |
Instantly use the relative enchancment.
Use a first-order Taylor enlargement to estimate its variance |
|
How a lot distinction are the 2 strategies making in observe?
To match the 2 strategies, we ran a simulation to verify if the pattern sizes deliberate for relative enchancment truly attain the ability we would like in precise exams. The diagram under exhibits how we did the simulation.
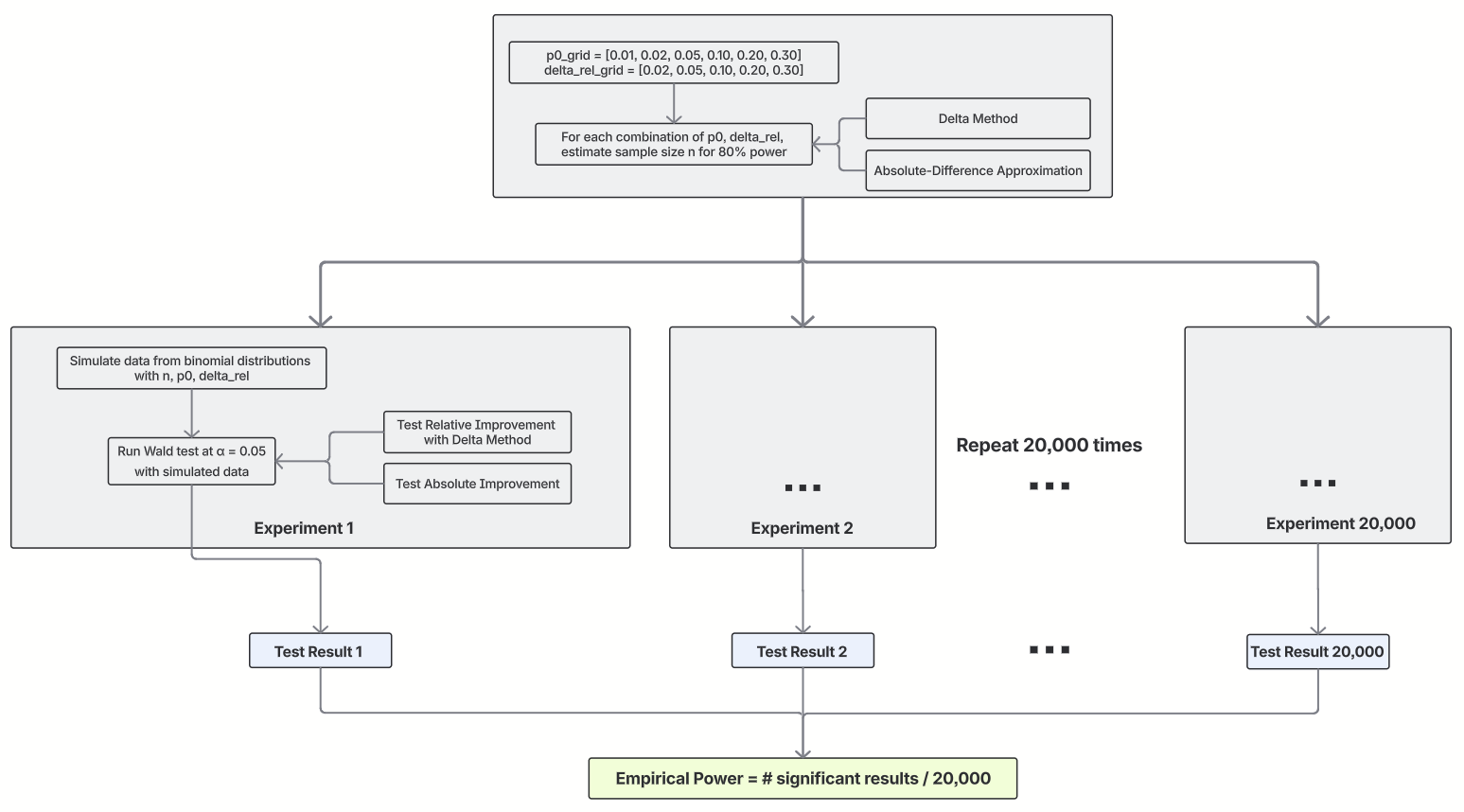 Notice that we additionally assorted the precise exams within the simulation. Like with the 2 methods to estimate pattern dimension, if you wish to verify for relative enchancment, you may flip the relative raise into an absolute distinction and take a look at that, or you need to use the delta technique to check the relative enchancment straight. The simulation outcomes are proven under.
Notice that we additionally assorted the precise exams within the simulation. Like with the 2 methods to estimate pattern dimension, if you wish to verify for relative enchancment, you may flip the relative raise into an absolute distinction and take a look at that, or you need to use the delta technique to check the relative enchancment straight. The simulation outcomes are proven under.
 Picture: Simulation outcomes testing absolute imply distinction
Picture: Simulation outcomes testing absolute imply distinction
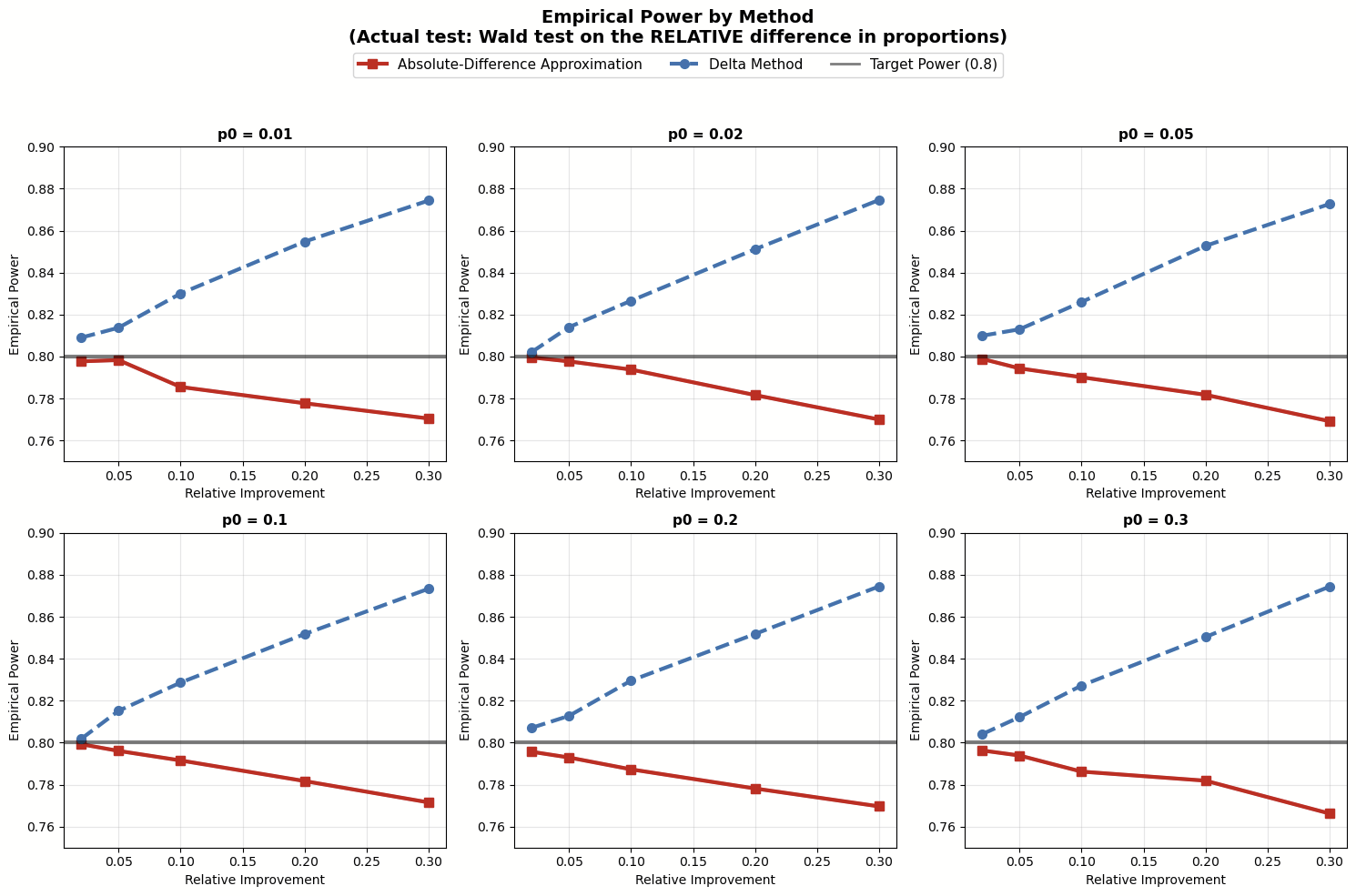 Picture: Simulation outcomes testing relative imply distinction
Picture: Simulation outcomes testing relative imply distinction
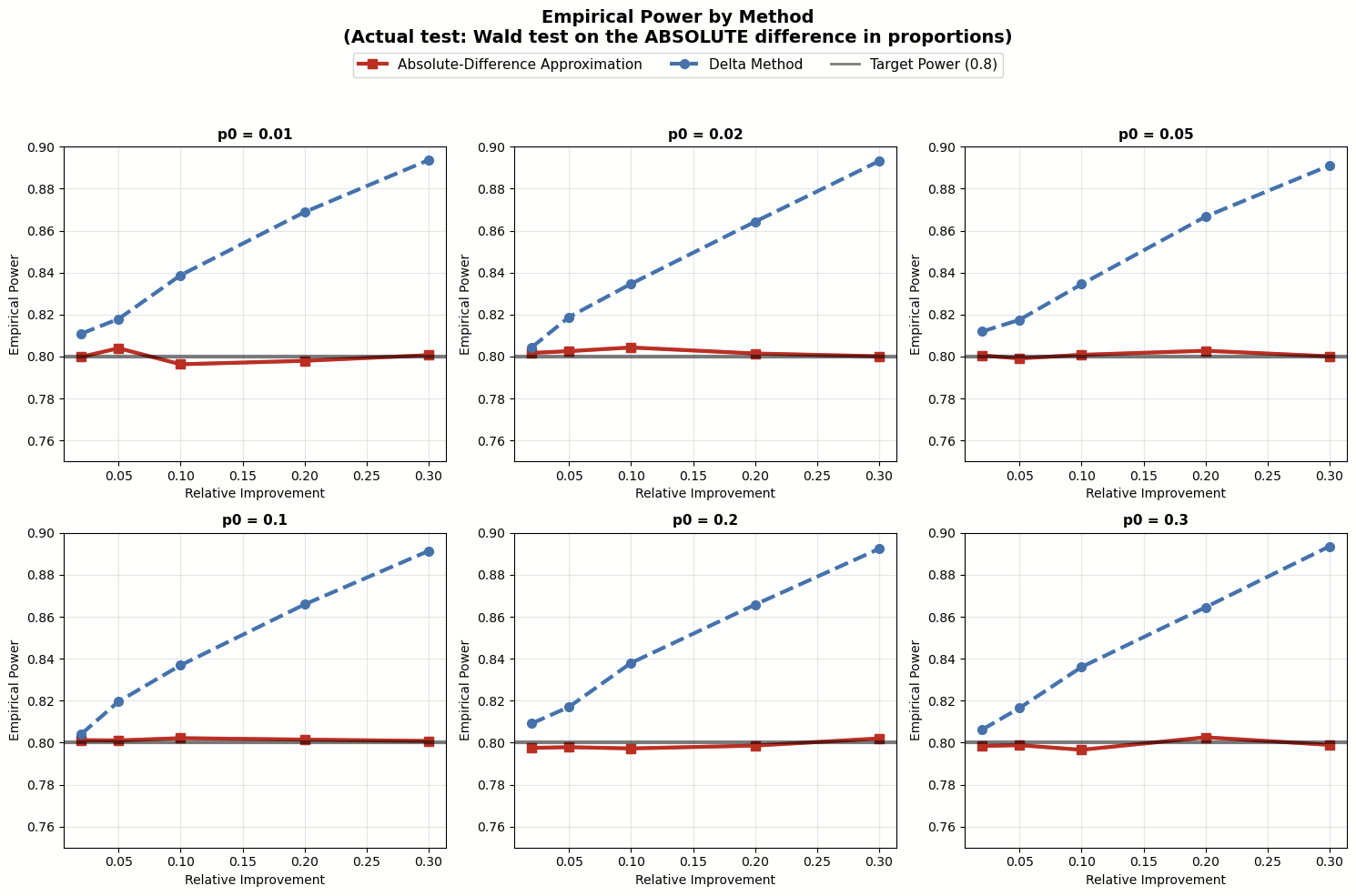
The simulation outcomes counsel:
- When testing absolute imply distinction, the Absolute-Distinction Approximation for planning pattern dimension matchesour purpose of 80% energy. Alternatively, the Delta Technique tends to overestimate the pattern sizes wanted.
- When testing relative imply distinction with the delta technique, the Absolute-Distinction Approximation normally underestimates the pattern sizes as a result of it underestimates the variance. The issue of being underpowered will get worse because the relative enchancment grows.
These findings spotlight our urged finest observe earlier: make sure that your pattern dimension estimation matches the statistical take a look at you intend to make use of. In the event you’re utilizing an absolute distinction take a look at to estimate a relative distinction take a look at, go together with the Absolute-Distinction Approximation to your pattern dimension. However in case you run the relative distinction take a look at straight utilizing the delta technique, then use that technique to estimate pattern dimension. (Selecting between these two exams for relative enchancment is past the scope of this publish, however simply know that the approximation take a look at skips over some uncertainty within the denominator and is not your best option within the trade.)
At Optimizely, we use the delta technique to check relative enchancment, so our pattern dimension estimation additionally makes use of the delta method.
What pattern dimension formulation inform about pattern dimension discount
When folks plan pattern sizes, they normally need them as small as attainable to maintain experiments fast. Two importantfactors that affect pattern dimension typically get missed in pattern dimension formulation: the minimal detectable impact (MDE) within the denominator and the metric variance within the numerator. These components can truly assist decrease the wanted pattern dimension. In all formulation, if we repair α at 0.05 and β at 0.2 (80% energy), having decrease metric variance or/and a much bigger MDE means you want a smaller pattern dimension.
This brings up two sensible suggestions:
- When you’ve recognized candidate metrics that your experimental adjustments can truly transfer and that the enterprise cares about probably the most, you may have a look at historic information to choose the metric with decrease variance as the first metric. (With historic information, you may have the ability to cut back pattern dimension additional by utilizing methods like CUPED)
- If stakeholders are speeding you, clarify that selecting a much bigger MDE will help end the experiment on time. Butthey ought to know this implies there is a increased probability of lacking small results, so they may wish to rethink whatthe experiment is for. And no matter MDE you choose should nonetheless be lifelike — inflating it past what’s believable merely to complete sooner makes the experiment meaningless.
References
Chow, S. C., Shao, J., Wang, H., & Lokhnygina, Y. (2017). Pattern dimension calculations in scientific analysis. Chapman and Corridor/CRC. (pp. 13-15, 77)
Stuart, A., Ord, Ok. & Arnold, S. (2004). Kendall’s superior concept of statistics, classical inference, and the linear mannequin. John Wiley & Sons. (pp. 190-191)
Casella, G., & Berger, R. (2002). Statistical inference (2ed). Chapman and Corridor/CRC. (p. 385)
Davison, A. C. (2003). Statistical fashions. Cambridge College Press. (p. 334)
Cox, D. R., & Hinkley, D. V. (1979). Theoretical statistics. CRC Press. (pp. 103-104)
Belle, G. van. (2011). Statistical Guidelines of Thumb. John Wiley & Sons.
Wu, J., & Ding, P. (2021). Randomization exams for weak null hypotheses in randomized experiments. Journal of the American Statistical Affiliation, 116(536), 1898-1913.
Ding, P. (2024). A primary course in causal inference. Chapman and Corridor/CRC. pp.25-55
Imbens, G. W., & Rubin, D. B. (2015). Causal inference in statistics, social, and biomedical sciences. Cambridge college press. pp.83-112
Source link