


{kind=link}

Information Scraper for web sites
Information Excavator – highly effective C# server for crawling, scraping and saving any information from web sites. With the information excavator, you merely can scrape any information from any web site and export it into XLSX / CSV / MySQL / JSON. It’s a extremely easy and quick resolution with minimal entry level for everybody who need to mine information and don’t need to learn lots of tutorials.
Scraping course of working based mostly on .css and x-path selectors. Utility contains crawling server, grabbing server (scraping server) and IO server. Every server written in pure multi-threaded mannequin. Do you’ve gotten 8-cores processor? Good. Could also be, 12-cores? Excellent! The information excavator is instantly depended out of your PC high quality – he can works at highly effective servers. Typically, with a very good {hardware}, you possibly can enhance the information excavator to scraping web sites in “monster-mode”, and make 100, 500, 1000 scraping requests per second. Do you actually need to making skilled information mining? Okay, then simply use the Information excavator and overlook about different methods to mine information. Our resolution is the actually quick native server, written with pure high quality and with the most effective particular algoritms.
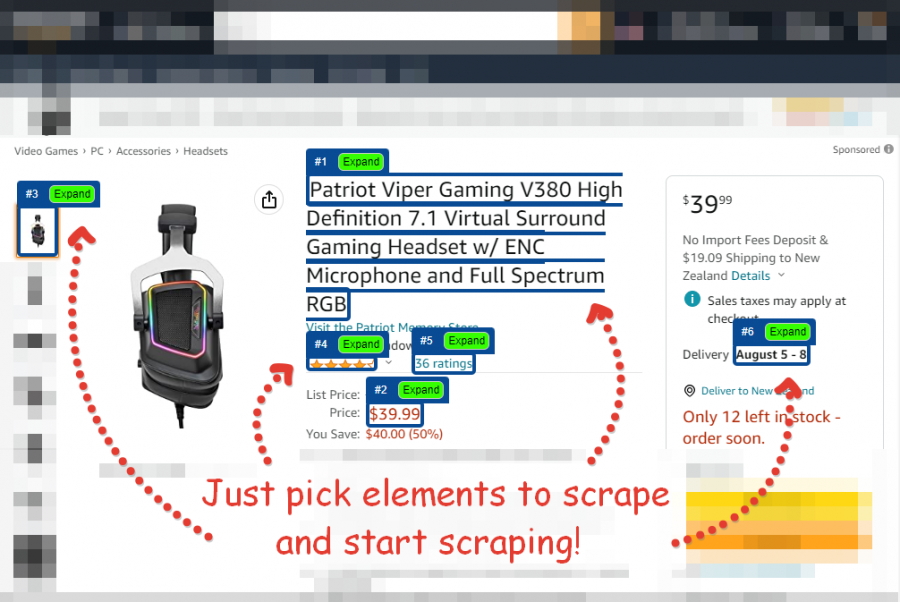

Most of present information scraping options from opponents works fairly linear – you have to do each scraping step your self with browser plugin. Alternatively you have to to make use of page-to-page switching with urgent “Scrape information” magic button. After all, there’s loads of skilled data-mining options with excessive value and authentic high quality. However there’s not so many good options with good value and efficiency.
The Information Excavator can be utilized in most of conditions when it’s essential to extract any-typed information from any web site. Could also be, you need to create a e-commerce challenge and also you seek for a items information supply? Could also be you need to construct a service for costs evaluating? Could also be you’re a huge information specialist and should put together some information set for analysing? Any job in information scraping conceivable you possibly can clear up with the Information Excavator software.
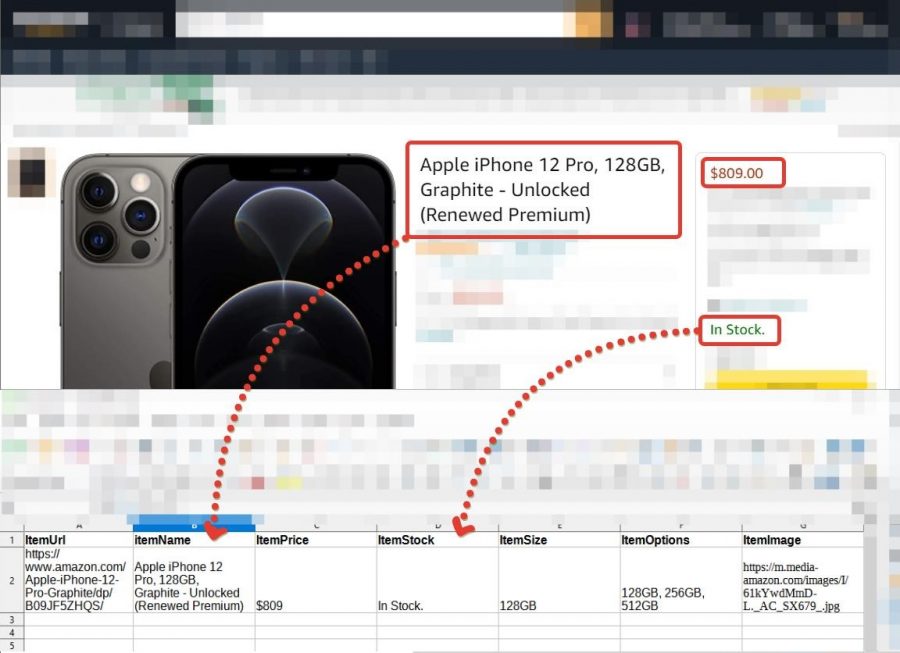
For instance, check out how nicely our program manages to extract information from the Aliexpress web site. We merely take any web page and sequentially extract all information from it. You don’t want any settings – we now have a ready-made configuration.
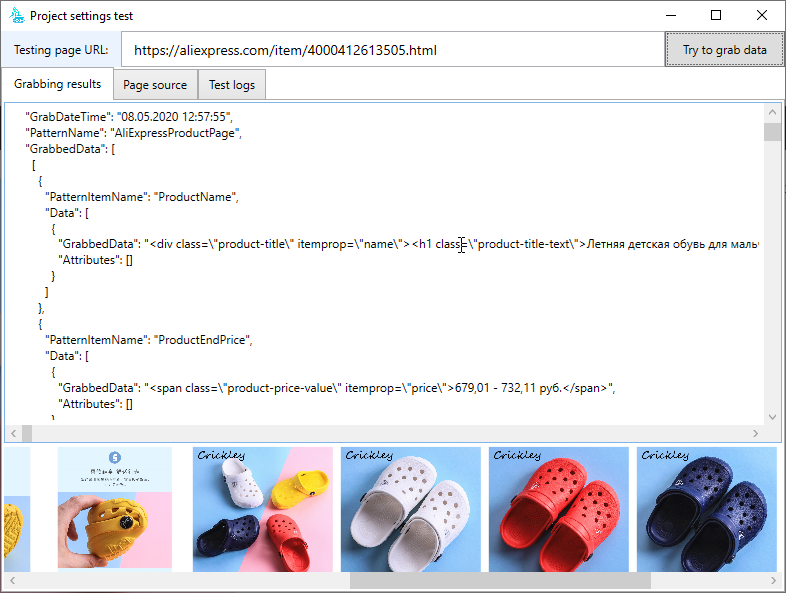
What are the important thing variations between our software and others? We provide an entire scraping server. It actually does all the pieces it’s essential to extract information, from a number of settings and computerized .css selectors, to exporting information on the fly. Primarily based on our software, you possibly can create giant methods for computerized information scraping and evaluation. Our software contains many feedback on the supply codes. You received’t have any hassle understanding the interface construction and calls to system libraries. Our predominant delight is multithreaded scraping. Now we have made the applying parallel in all the pieces that was attainable. You possibly can create a number of initiatives and extract information from a number of websites concurrently. Every challenge has its personal thread pool (oh sure!) which could be elevated or decreased. Every challenge has a separate thread pool for scanning pages, and a separate thread pool for parsing downloaded pages.
Our software relies on the Chromium Embedded Framework (CEF) – that’s, it has a full-fledged Chromium browser constructed into it. This lets you extract information from any web site, even these the place content material is just not instantly downloaded or requires a login. This essentially distinguishes us from our opponents – our software is appropriate for scraping virtually any web site.
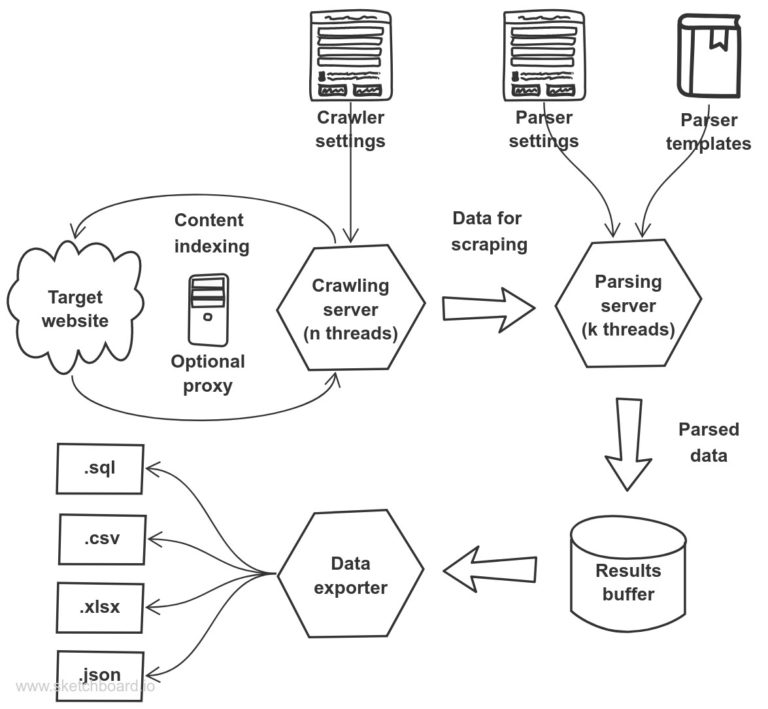
The way it works
Our software is written in C#. Sure, it’s a full C# (.NET) scraping server. We used a multi-threaded mannequin so as to extract information from any web site as quick as attainable. Our software helps authorization and interplay with websites through JS. We attempt to make the interface easy, below which there’s a reasonably highly effective engine.
What duties you possibly can clear up?
- Scrape any information from any e-commerce web sites, like: amazon, ebay, aliexpress, walmart and plenty of others.
- Scrape any information from any social community: fb, twitter, instagram, linked in and others.
- Scrape any information from any cryptocurrency trade web site.
- Scrape any information from any provider web site.
- Export of scraped information: .xlsx / .xls / .json /.csv and others.
Export of outcomes
Upon getting collected information from some web site, you possibly can export it. We help export in xlsx, csv, json, mysql codecs. We write textual content information right into a file and place pictures from the positioning in a folder subsequent to the file. These pictures are linked to the information through the “pictures” column within the desk, or through the corresponding parameter within the JSON object (relying on the export format you select).
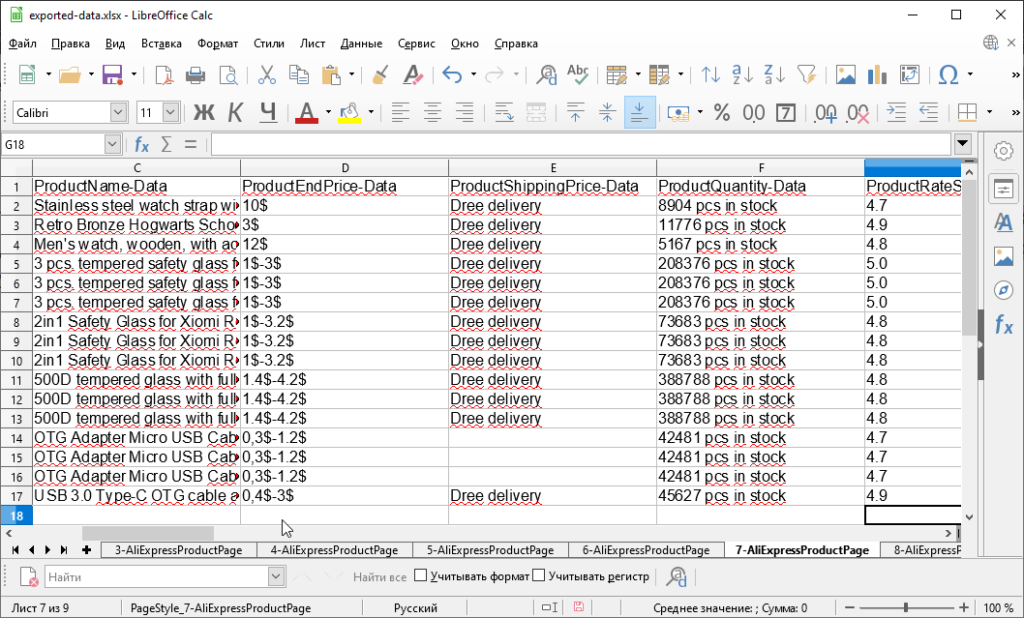
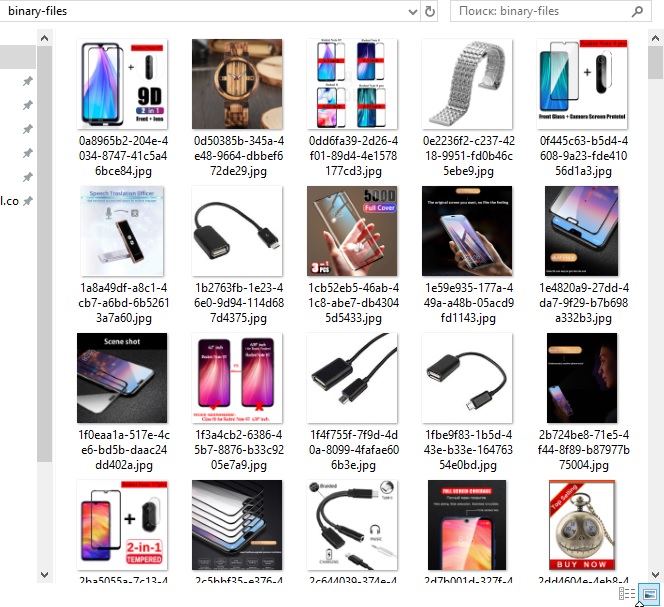
Particular: working with photos and BLOB information
Our system is ready to work with pictures and different binary recordsdata. You possibly can extract actually any info from the goal web page – pictures, media recordsdata, binary information and so forth. Even when the picture is packaged within the information:[blob] format, the system will accurately course of it. All pictures are saved in recordsdata in your laborious drive. When exporting, we gather the archive, which comprises the exported information, in addition to a set of pictures.
App modules and libraries
Our scraper is written in C#, platform .NET Framework. It contains the next modules and libraries:
- CEF (Chromium Embedded Framework)>
- CEFSharp – connector between C# and CEF
- EPPlus – working with Excel
- RestSharp – working with distant calls ($_GET / $_POST)
- ExcavatorSharp – library for parallel crawling and scraping
- HtmlAgilityPack – parsing information from DOM
- Newtonsoft.JSON – packing information into JSON format
- log4net – information logging
Please notice that this isn’t a magic bullet that can robotically google, discover the websites you need and extract information from them with out your participation.
At the least of data you need to perceive how .css-selectors or xpath work. You also needs to be accustomed to normal net information extraction expertise equivalent to proxying, $_GET and $_POST queries, web page scanning administration by way of templates and common expressions.
Additionally, if you wish to extract information to fill your web site, you have to perceive that the system scans the information after which exports it to some format, or sends it through some http(s) hyperlink. The system doesn’t know tips on how to robotically insert information into your web site.
Further choices:
Totally free help! We are actually simply coming into the market and recruiting an viewers for our resolution. We went loopy and laid out the supply codes for our software. If you wish to construct an answer for information scraping based mostly on our expertise, we shall be glad to advise you!
Options:
- Pure multi-threadeded scraping (you possibly can scrape many various web sites in parallel)
- Multithreaded crawling – get information from web site in parallel mode
- Browser-engine crawling – parse information from downloaded pages in parallel mode
- Help for a number of proxy servers
- $_GET and $_POST person args – obtain pages with set of args
- Dynamic content material crawling – get content material created with JS, ActiveX and different. Watch for AJAX calls
- Interplay of person JS-code with pages of the positioning
- Robots.txt ans Sitemaps help
- Pages reindexing help
- Person-defined crawling behaviors
- Respect or disrespect for chosen hyperlinks
- Evaluation of robots.txt below the chosen person agent
- Multi-dimensional information extracting
- Multithreaded information extraction
- Exporting information: .xls, .xlsx, .csv, .sql, .json
- Exporting information on-line through HTTP url
- Overview grabbed information into UI
- Import&Export initiatives settings
- Venture settings testing on specified web page
- Seize solely hyperlinks from specified web page (if you would like)
- Venture efficiency metrics board
- Forcing specified hyperlinks reindexing
- Grabbing web site hyperlinks administration panel
- Tasks interactive dashboard
- Helps attributes downloading – blobs, pictures
Starter information:
You should utilize our software each for easy information scraping and for creating your individual purposes. If you wish to merely extract information from a sure web site – use Setup and set up the already assembled model. If you wish to develop – use the Visible Studio challenge.
The way it works for end-user:
- Create new challenge and full challenge settings (or use default settings set)
- Specify a set of hyperlinks to scraping
- Begin challenge
- Wait whereas software will scrape specified hyperlinks
- Export information to preffered format, like a .xls / .xlsx /.csv / .json
How you can create new challenge (much less then 3 minutes):
- Click on on “New challenge (specific)”
- Full goal web site deal with
- Click on on “Auto detect .CSS-selectors”
- Click on on “Create new challenge”
DONE! System will robotically detect .CSS selectors and set all settings to default values.
What scraping duties can I clear up with the applying?
With our C# scraper you possibly can extract information from most well-known websites. Principally, it doesn’t matter what the positioning seems to be like or the way it shows the information. Even when a web site requires a login and password, or shows dynamic content material with a delay – we are able to nonetheless extract information from its pages. You possibly can scrape information, for instance, from the next web sites:

- Amazon.com
- Walmart.com
- Aliexpress.com
- Ebay.com
- Google.com
- Craigslist.org
- Sears.com
- Kroger.com
- Costco.com
- Google.com
- Bing.com
- Wikipedia.org
- Nytimes.com
- Nypost.com
- Washingtonpost.com
- Wsj.com
- Hr.com
- Iherb.com
- And rather more!
At your disposal is a ready-made library of normal initiatives. No must cope with something – simply use the ready-made settings from the listing!
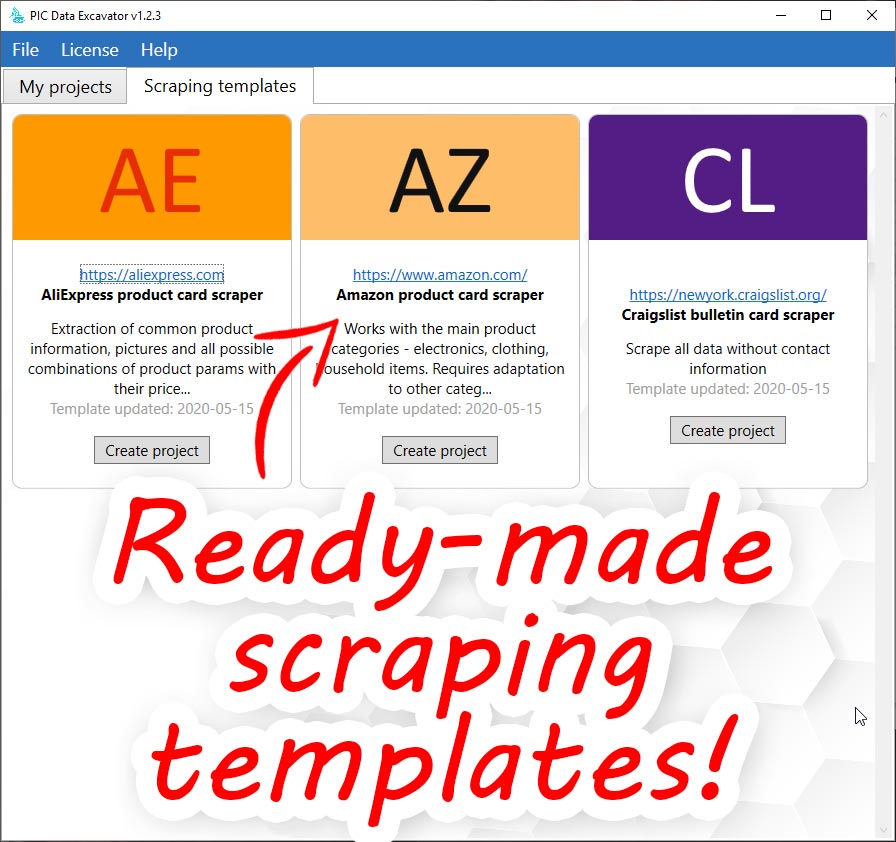
Necessities for information scraper utilization:
- VC++ 2019 Redistributable
- .NET Framework 4.7.2
- X64 processor (as a result of most of scraping duties makes use of 1Gb of RAM as minimal)
- Free area on HDD (1Gb+)
- Home windows 7, Home windows 8, Home windows 10
- IDE: VIsual Studio 2019 / Builders solely
Success story
Click on on picture to learn extra, or observe direct link.


Hyperlinks and docs:
Web site URL: https://data-excavator.com
Widespread questions and UI: https://data-excavator.com/faq/
Core library info: https://data-excavator.com/excavatorsharp-web-scraping/
Core library docs: https://data-excavator.com/excavatorsharp-docs/
Contact us: https://data-excavator.com/contact/
If you’re an developer, see readme file after buying.
Additional providers in information scraping and lead generagion:
Listed below are hyperlinks to helpful providers for information scraping and lead era. We use them ourselves and may advocate them to our purchasers.

