


{kind=link}
![]()
Redirects are important to each web site’s upkeep, and managing redirects turns into actually difficult when search engine optimization professionals cope with web sites containing thousands and thousands of pages.
Examples of conditions the place it’s possible you’ll have to implement redirects at scale:
- An ecommerce website has numerous merchandise which are now not offered.
- Outdated pages of stories publications are now not related or lack historic worth.
- Itemizing directories that comprise outdated listings.
- Job boards the place postings expire.
Why Is Redirecting At Scale Important?
It might assist enhance consumer expertise, consolidate rankings, and save crawl price range.
You would possibly take into account noindexing, however this doesn’t cease Googlebot from crawling. It wastes crawl budget because the variety of pages grows.
From a consumer expertise perspective, touchdown on an outdated hyperlink is irritating. For instance, if a consumer lands on an outdated job itemizing, it’s higher to ship them to the closest match for an energetic job itemizing.
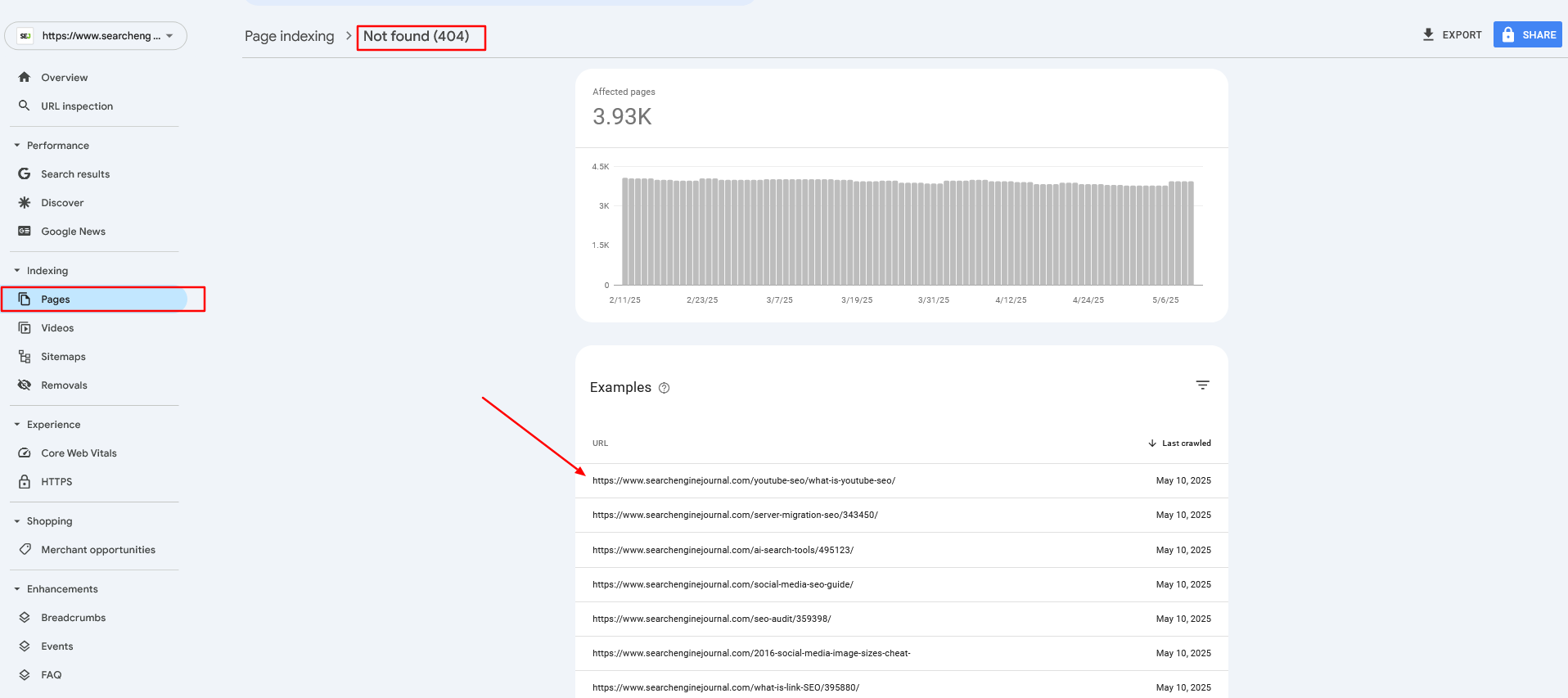
At Search Engine Journal, we get many 404 hyperlinks from AI chatbots due to hallucinations as they invent URLs that by no means existed.
We use Google Analytics 4 and Google Search Console (and generally server logs) experiences to extract these 404 pages and redirect them to the closest matching content material primarily based on article slug.
When chatbots cite us by way of 404 pages, and other people preserve coming via damaged hyperlinks, it’s not a great consumer expertise.
Put together Redirect Candidates
To start with, learn this post to learn to create a Pinecone vector database. (Please notice that on this case, we used “primary_category” as a metadata key vs. “class.”)
To make this work, we assume that every one your article vectors are already saved within the “article-index-vertex” database.
Put together your redirect URLs in CSV format like on this sample file. That might be current articles you’ve determined to prune or 404s out of your search console experiences or GA4.
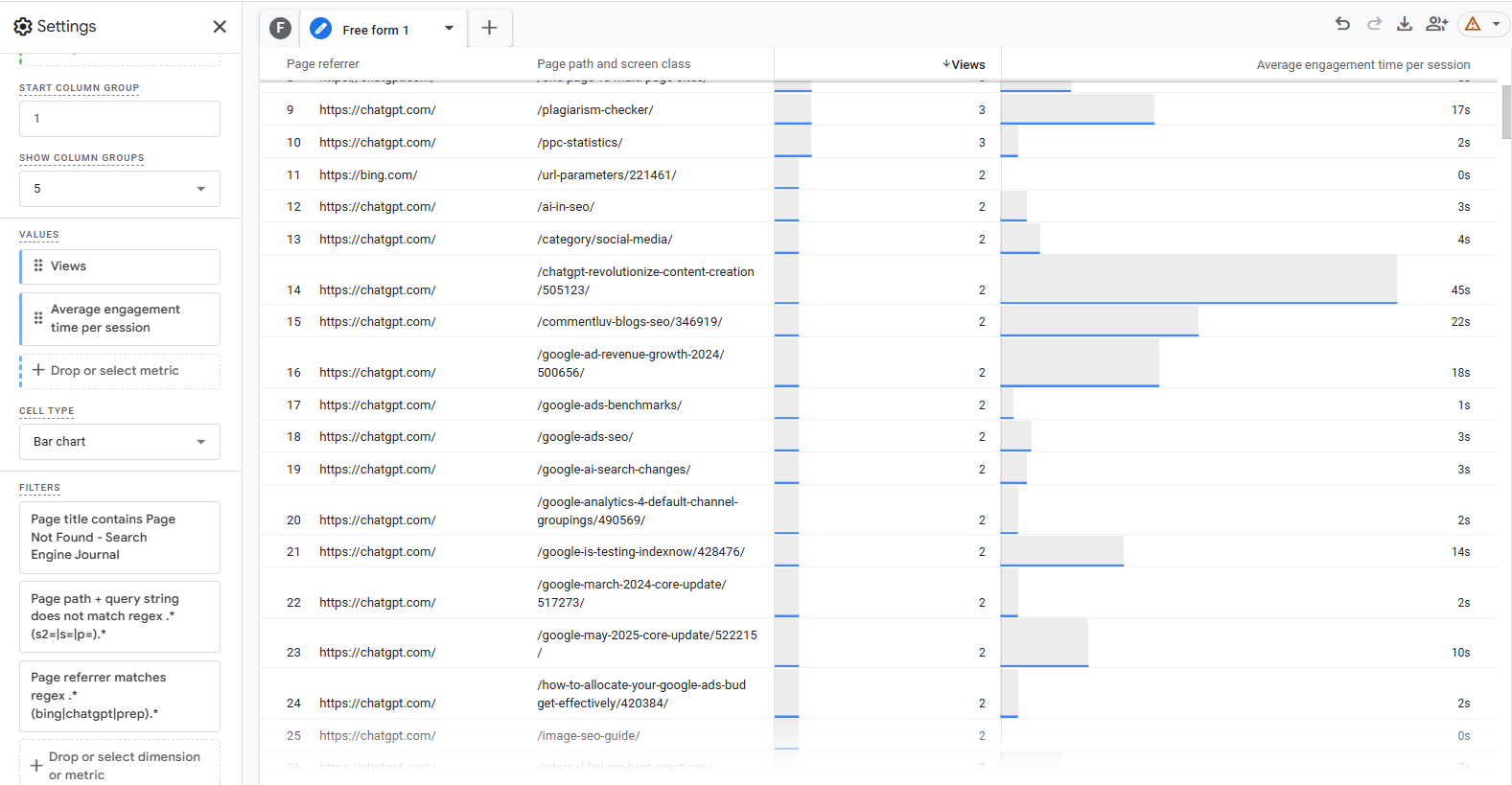
 Pattern file with URLs to be redirected (Screenshot from Google Sheet, Could 2025)
Pattern file with URLs to be redirected (Screenshot from Google Sheet, Could 2025)Non-obligatory “primary_category” info is metadata that exists along with your articles’ Pinecone data while you created them and can be utilized to filter articles from the identical class, enhancing accuracy additional.
In case the title is lacking, for instance, in 404 URLs, the script will extract slug phrases from the URL and use them as enter.
Generate Redirects Utilizing Google Vertex AI
Obtain your Google API service credentials and rename them as “config.json,” add the script beneath and a sample file to the identical listing in Jupyter Lab, and run it.
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Non-obligatory, Checklist, Dict, Any
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import GoogleAPIError
from pinecone import Pinecone, PineconeException
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Import tenacity for retry mechanism. Tenacity gives a decorator so as to add retry logic
# to capabilities, making them extra strong in opposition to transient errors like community points or API charge limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optionally available, preserve if operating in Jupyter).
# That is helpful for interactive environments to indicate progress with out cluttering the output.
from IPython.show import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Outline configurable parameters for the script. These might be simply adjusted
# with out modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the enter CSV file containing URLs to be redirected.
# Anticipated columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file the place the generated redirect map can be saved.
PINECONE_API_KEY = "YOUR_PINECONE_KEY" # Your API key for Pinecone. Substitute along with your precise key.
PINECONE_INDEX_NAME = "article-index-vertex" # The identify of the Pinecone index the place article vectors are saved.
GOOGLE_CRED_PATH = "config.json" # Path to your Google Cloud service account credentials JSON file.
EMBEDDING_MODEL_ID = "text-embedding-005" # Identifier for the Vertex AI textual content embedding mannequin to make use of.
TASK_TYPE = "RETRIEVAL_QUERY" # The duty kind for the embedding mannequin. Attempt with RETRIEVAL_DOCUMENT vs RETRIEVAL_QUERY to see the distinction.
# This influences how the embedding vector is generated for optimum retrieval.
CANDIDATE_FETCH_COUNT = 3 # Variety of potential redirect candidates to fetch from Pinecone for every enter URL.
TEST_MODE = True # If True, the script will course of solely a small subset of the enter knowledge (MAX_TEST_ROWS).
# Helpful for testing and debugging.
MAX_TEST_ROWS = 5 # Most variety of rows to course of when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to keep away from hitting charge limits).
PUBLISH_YEAR_FILTER: Checklist[int] = [] # Non-obligatory: Checklist of years to filter Pinecone outcomes by 'publish_year' metadata.
# If empty, no 12 months filtering is utilized.
LOG_BATCH_SIZE = 5 # Variety of URLs to course of earlier than flushing the outcomes to the output CSV.
# This helps in saving progress incrementally and managing reminiscence.
MIN_SLUG_LENGTH = 3 # Minimal size for a URL slug phase to be thought-about significant for embedding.
# Shorter segments could be noise or much less descriptive.
# Retry configuration for API calls (Vertex AI and Pinecone).
# These parameters management how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Most variety of instances to retry an API name earlier than giving up.
INITIAL_RETRY_DELAY = 1 # Preliminary delay in seconds earlier than the primary retry.
# Subsequent retries can have exponentially growing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
stage=logging.INFO, # Set the logging stage to INFO, that means INFO, WARNING, ERROR, CRITICAL messages can be proven.
format="%(asctime)s %(levelname)s %(message)s" # Outline the format of log messages (timestamp, stage, message).
)
# ─── INITIALIZE GOOGLE VERTEX AI ───────────────────────────────────────────────
# Set the GOOGLE_APPLICATION_CREDENTIALS atmosphere variable to level to the
# service account key file. This permits the Google Cloud shopper libraries to
# authenticate routinely.
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = GOOGLE_CRED_PATH
strive:
# Load credentials from the required JSON file.
credentials, project_id = load_credentials_from_file(GOOGLE_CRED_PATH)
# Initialize the Vertex AI shopper with the venture ID and credentials.
# The placement "us-central1" is specified for the AI Platform providers.
aiplatform.init(venture=project_id, credentials=credentials, location="us-central1")
logging.data("Vertex AI initialized.")
besides Exception as e:
# Log an error if Vertex AI initialization fails and re-raise the exception
# to cease script execution, as it is a essential dependency.
logging.error(f"Did not initialize Vertex AI: {e}")
elevate
# Initialize the embedding mannequin as soon as globally.
# This can be a essential optimization for "Useful resource Administration for Embedding Mannequin".
# Loading the mannequin takes time and assets; doing it as soon as avoids repeated loading
# for each URL processed, considerably enhancing efficiency.
strive:
GLOBAL_EMBEDDING_MODEL = TextEmbeddingModel.from_pretrained(EMBEDDING_MODEL_ID)
logging.data(f"Textual content Embedding Mannequin '{EMBEDDING_MODEL_ID}' loaded.")
besides Exception as e:
# Log an error if the embedding mannequin fails to load and re-raise.
# The script can't proceed with out the embedding mannequin.
logging.error(f"Did not load Textual content Embedding Mannequin: {e}")
elevate
# ─── INITIALIZE PINECONE ──────────────────────────────────────────────────────
# Initialize the Pinecone shopper and connect with the required index.
strive:
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.data(f"Related to Pinecone index '{PINECONE_INDEX_NAME}'.")
besides PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a essential dependency for locating redirect candidates.
logging.error(f"Pinecone init error: {e}")
elevate
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical type by:
1. Stripping question strings (e.g., `?param=worth`) and URL fragments (e.g., `#part`).
2. Dealing with URL-encoded fragment markers (`%23`).
3. Preserving the trailing slash if it was current within the unique URL's path.
This ensures consistency with the unique website's URL construction.
Args:
url (str): The enter URL.
Returns:
str: The canonicalized URL.
"""
# Take away question parameters and URL fragments.
temp = url.break up('?', 1)[0].break up('#', 1)[0]
# Verify for URL-encoded fragment markers and take away them.
enc_idx = temp.decrease().discover('%23')
if enc_idx != -1:
temp = temp[:enc_idx]
# Decide if the unique URL path ended with a trailing slash.
has_slash = urlparse(temp).path.endswith('/')
# Take away any trailing slash briefly for constant processing.
temp = temp.rstrip('/')
# Re-add the trailing slash if it was initially current.
return temp + ('/' if has_slash else '')
def slug_from_url(url: str) -> str:
"""
Extracts and joins significant, non-numeric path segments from a canonical URL
to type a "slug" string. This slug can be utilized as textual content for embedding when
a URL's title just isn't accessible.
Args:
url (str): The enter URL.
Returns:
str: A hyphen-separated string of related slug elements.
"""
clear = canonical_url(url) # Get the canonical model of the URL.
path = urlparse(clear).path # Extract the trail element of the URL.
segments = [seg for seg in path.split('/') if seg] # Break up path into segments and take away empty ones.
# Filter segments primarily based on standards:
# - Not purely numeric (e.g., '123' is excluded).
# - Size is bigger than or equal to MIN_SLUG_LENGTH.
# - Comprises at the least one alphanumeric character (to exclude purely particular character segments).
elements = [seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'[A-Za-z0-9]', seg)]
return '-'.be a part of(elements) # Be part of the filtered elements with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for GoogleAPIError. This makes the embedding technology
# extra resilient to transient points like community issues or Vertex AI charge limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
cease=stop_after_attempt(MAX_RETRIES), # Cease retrying after a most variety of makes an attempt.
retry=retry_if_exception_type(GoogleAPIError), # Solely retry if a GoogleAPIError happens.
reraise=True # Re-raise the exception if all retries fail, permitting the calling operate to deal with it.
)
def generate_embedding(textual content: str) -> Non-obligatory[List[float]]:
"""
Generates a vector embedding for the given textual content utilizing the globally initialized
Vertex AI Textual content Embedding Mannequin. Consists of retry logic for API calls.
Args:
textual content (str): The enter textual content (e.g., URL title or slug) to embed.
Returns:
Non-obligatory[List[float]]: A listing of floats representing the embedding vector,
or None if the enter textual content is empty/whitespace or
if an sudden error happens after retries.
"""
if not textual content or not textual content.strip():
# If the textual content is empty or solely whitespace, no embedding might be generated.
return None
strive:
# Use the globally initialized mannequin to get embeddings.
# That is the "Useful resource Administration for Embedding Mannequin" optimization.
inp = TextEmbeddingInput(textual content, task_type=TASK_TYPE)
vectors = GLOBAL_EMBEDDING_MODEL.get_embeddings([inp], output_dimensionality=768)
return vectors[0].values # Return the embedding vector (record of floats).
besides GoogleAPIError as e:
# Log a warning if a GoogleAPIError happens, then re-raise to set off the `tenacity` retry mechanism.
logging.warning(f"Vertex AI error throughout embedding technology (retrying): {e}")
elevate # The `reraise=True` within the decorator will catch this and retry.
besides Exception as e:
# Catch another sudden exceptions throughout embedding technology.
logging.error(f"Surprising error producing embedding: {e}")
return None # Return None for non-retryable or remaining failed makes an attempt.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an enter CSV, producing
embeddings, querying Pinecone for related articles, and figuring out
appropriate redirect candidates.
Args:
input_csv (str): Path to the enter CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Variety of candidates to fetch from Pinecone.
test_mode (bool): If True, course of solely a restricted variety of rows.
"""
# Learn the enter CSV file right into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that every one required columns are current within the DataFrame.
if not required.issubset(df.columns):
elevate ValueError(f"Enter CSV should have columns: {required}")
# Create a set of canonicalized enter URLs for environment friendly lookup.
# That is used to forestall an enter URL from redirecting to itself or one other enter URL,
# which may create redirect loops or redirect to a web page that can be being redirected.
input_urls = set(df["URL"].map(canonical_url))
start_idx = 0
# Implement resume performance: if the output CSV already exists,
# attempt to discover the final processed URL and resume from the following row.
if os.path.exists(output_csv):
strive:
prev = pd.read_csv(output_csv)
besides EmptyDataError:
# Deal with case the place the output CSV exists however is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the final URL that was processed and written to the output file.
final = prev["URL"].iloc[-1]
# Discover the index of this final URL within the unique enter DataFrame.
idxs = df.index[df["URL"].map(canonical_url) == final].tolist()
if idxs:
# Set the beginning index for processing to the row after the final processed URL.
start_idx = idxs[0] + 1
logging.data(f"Resuming from row {start_idx} after {final}.")
# Decide the vary of rows to course of primarily based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc[start_idx:end_idx] # Choose a slice of the DataFrame for testing.
logging.data(f"Take a look at mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc[start_idx:] # Course of all remaining rows.
logging.data(f"Processing rows {start_idx} to {len(df)-1}.")
whole = len(df_proc) # Complete variety of URLs to course of on this run.
processed = 0 # Counter for efficiently processed URLs.
batch: Checklist[Dict[str, Any]] = [] # Checklist to retailer outcomes earlier than flushing to CSV.
# Iterate over every row (URL) within the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row["URL"] # Unique URL from the enter CSV.
url = canonical_url(raw_url) # Canonicalized model of the URL.
# Get title and class, dealing with potential lacking values by defaulting to empty strings.
title = row["Title"] if isinstance(row["Title"], str) else ""
class = row["primary_category"] if isinstance(row["primary_category"], str) else ""
# Decide the textual content to make use of for producing the embedding.
# Prioritize the 'Title' if accessible, in any other case use a slug derived from the URL.
if title.strip():
textual content = title
else:
slug = slug_from_url(raw_url)
if not slug:
# If no significant slug might be extracted, skip this URL.
logging.data(f"Skipping {raw_url}: inadequate slug context for embedding.")
proceed
textual content = slug.change('-', ' ') # Put together slug for embedding by changing hyphens with areas.
# Try to generate the embedding for the chosen textual content.
# This name is wrapped in a try-except block to catch remaining failures after retries.
strive:
embedding = generate_embedding(textual content)
besides GoogleAPIError as e:
# If embedding technology fails even after retries, log the error and skip this URL.
logging.error(f"Did not generate embedding for {raw_url} after {MAX_RETRIES} retries: {e}")
proceed # Transfer to the following URL.
if not embedding:
# If `generate_embedding` returned None (e.g., empty textual content or sudden error), skip.
logging.data(f"Skipping {raw_url}: no embedding generated.")
proceed
# Construct metadata filter for Pinecone question.
# This helps slim down search outcomes to extra related candidates (e.g., by class or publish 12 months).
filt: Dict[str, Any] = {}
if class:
# Break up class string by comma and strip whitespace for a number of classes.
cats = [c.strip() for c in category.split(",") if c.strip()]
if cats:
filt["primary_category"] = {"$in": cats} # Filter by classes current in Pinecone metadata.
if PUBLISH_YEAR_FILTER:
filt["publish_year"] = {"$in": PUBLISH_YEAR_FILTER} # Filter by specified publish years.
filt["id"] = {"$ne": url} # Exclude the present URL itself from the search outcomes to forestall self-redirects.
# Outline a nested operate for Pinecone question with retry mechanism.
# This ensures that Pinecone queries are additionally strong in opposition to transient errors.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10),
cease=stop_after_attempt(MAX_RETRIES),
retry=retry_if_exception_type(PineconeException), # Solely retry if a PineconeException happens.
reraise=True # Re-raise the exception if all retries fail.
)
def query_pinecone_with_retry(embedding_vector, top_k_count, pinecone_filter):
"""
Performs a Pinecone index question with retry logic.
"""
return index.question(
vector=embedding_vector,
top_k=top_k_count,
include_values=False, # We do not want the precise vector values within the response.
include_metadata=False, # We do not want the metadata within the response for this logic.
filter=pinecone_filter # Apply the constructed metadata filter.
)
# Try to question Pinecone for redirect candidates.
strive:
res = query_pinecone_with_retry(embedding, fetch_count, filt)
besides PineconeException as e:
# If Pinecone question fails after retries, log the error and skip this URL.
logging.error(f"Failed to question Pinecone for {raw_url} after {MAX_RETRIES} retries: {e}")
proceed # Transfer to the following URL.
candidate = None # Initialize redirect candidate to None.
rating = None # Initialize relevance rating to None.
# Iterate via the Pinecone question outcomes (matches) to discover a appropriate candidate.
for m in res.get("matches", []):
cid = m.get("id") # Get the ID (URL) of the matched doc in Pinecone.
# A candidate is appropriate if:
# 1. It exists (cid just isn't None).
# 2. It isn't the unique URL itself (to forestall self-redirects).
# 3. It isn't one other URL from the input_urls set (to forestall redirecting to a web page that is additionally being redirected).
if cid and cid != url and cid not in input_urls:
candidate = cid # Assign the primary legitimate candidate discovered.
rating = m.get("rating") # Get the relevance rating of this candidate.
break # Cease after discovering the primary appropriate candidate (Pinecone returns by relevance).
# Append the outcomes for the present URL to the batch.
batch.append({"URL": url, "Redirect Candidate": candidate, "Relevance Rating": rating})
processed += 1 # Increment the counter for processed URLs.
msg = f"Mapped {url} → {candidate}"
if rating just isn't None:
msg += f" ({rating:.4f})" # Add rating to log message if accessible.
logging.data(msg) # Log the mapping outcome.
# Periodically flush the batch outcomes to the output CSV.
if processed % LOG_BATCH_SIZE == 0:
out_df = pd.DataFrame(batch) # Convert the present batch to a DataFrame.
# Decide file mode: 'a' (append) if file exists, 'w' (write) if new.
mode="a" if os.path.exists(output_csv) else 'w'
# Decide if header ought to be written (just for new information).
header = not os.path.exists(output_csv)
# Write the batch to the CSV.
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
batch.clear() # Clear the batch after writing to free reminiscence.
if not test_mode:
# clear_output(wait=True) # Uncomment if operating in Jupyter and wish to clear output
clear_output(wait=True)
print(f"Progress: {processed} / {whole}") # Print progress replace.
time.sleep(QUERY_DELAY) # Pause for a brief delay to keep away from overwhelming APIs.
# After the loop, write any remaining objects within the batch to the output CSV.
if batch:
out_df = pd.DataFrame(batch)
mode="a" if os.path.exists(output_csv) else 'w'
header = not os.path.exists(output_csv)
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
logging.data(f"Accomplished. Complete processed: {processed}") # Log completion message.
if __name__ == "__main__":
# This block ensures that build_redirect_map is known as solely when the script is executed straight.
# It passes the user-defined configuration parameters to the primary operate.
build_redirect_map(INPUT_CSV, OUTPUT_CSV, CANDIDATE_FETCH_COUNT, TEST_MODE)
You will notice a take a look at run with solely 5 data, and you will note a brand new file known as “redirect_map.csv,” which accommodates redirect ideas.
When you make sure the code runs easily, you possibly can set the TEST_MODE boolean to true False and run the script for all of your URLs.
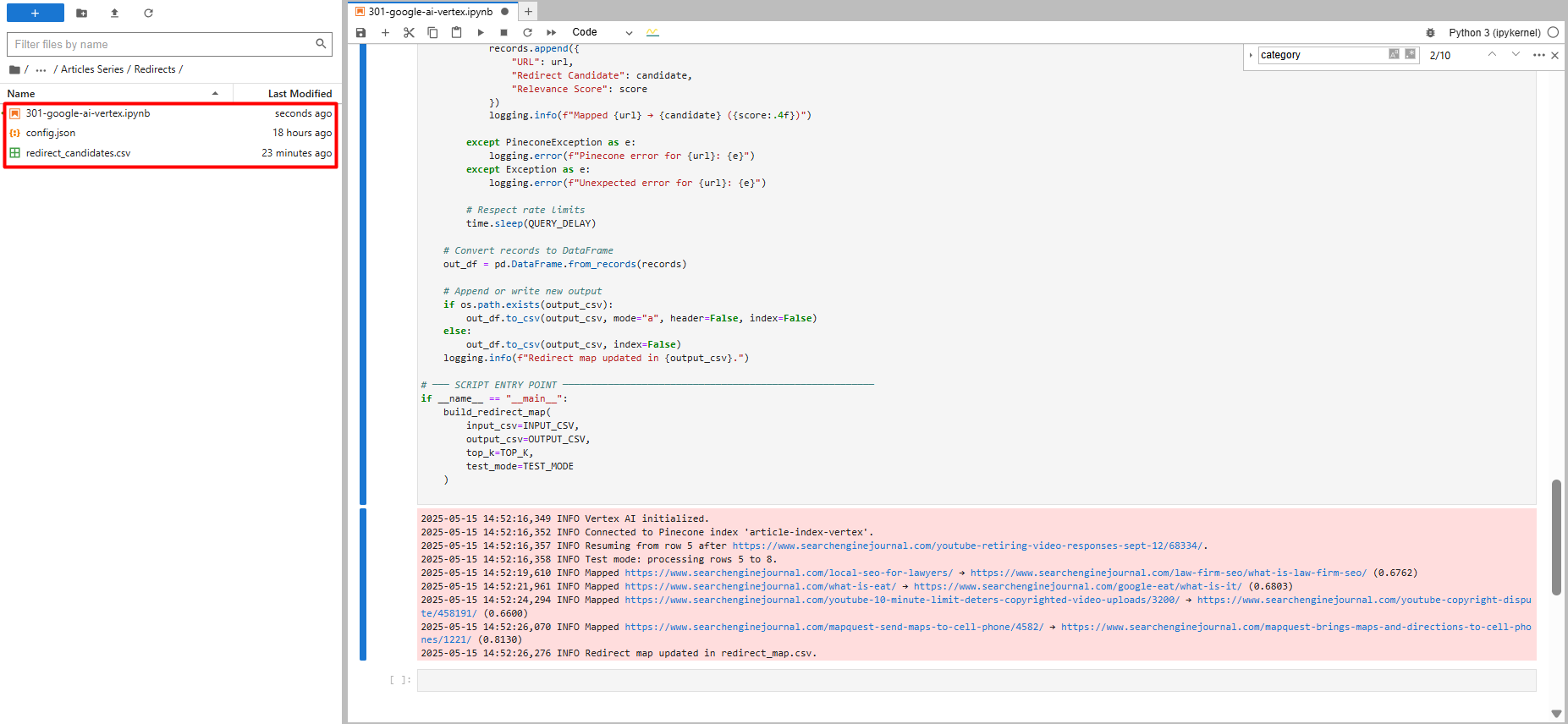 Take a look at run with solely 5 data (Picture from creator, Could 2025)
Take a look at run with solely 5 data (Picture from creator, Could 2025)If the code stops and also you resume, it picks up the place it left off. It additionally checks every redirect it finds in opposition to the CSV file.
This verify prevents choosing a database URL on the pruned record. Deciding on such a URL may trigger an infinite redirect loop.
For our pattern URLs, the output is proven beneath.
 Redirect candidates utilizing Google Vertex AI’s process kind RETRIEVAL_QUERY (Picture from creator, Could 2025)
Redirect candidates utilizing Google Vertex AI’s process kind RETRIEVAL_QUERY (Picture from creator, Could 2025)We are able to now take this redirect map and import it into our redirect supervisor within the content material administration system (CMS), and that’s it!
You possibly can see the way it managed to match the outdated 2013 information article “YouTube Retiring Video Responses on September 12” to the newer, extremely related 2022 information article “YouTube Adopts Function From TikTok – Reply To Feedback With A Video.”
Additionally for “/what-is-eat/,” it discovered a match with “/google-eat/what-is-it/,” which is a 100% excellent match.
This isn’t simply because of the energy of Google Vertex LLM high quality, but in addition the results of choosing the proper parameters.
Once I use “RETRIEVAL_DOCUMENT” as the duty kind when producing question vector embeddings for the YouTube information article proven above, it matches “YouTube Expands Group Posts to Extra Creators,” which continues to be related however not nearly as good a match as the opposite one.
For “/what-is-eat/,” it matches the article “/reimagining-eeat-to-drive-higher-sales-and-search-visibility/545790/,” which is not so good as “/google-eat/what-is-it/.”
Should you wished to seek out redirect matches out of your contemporary articles pool, you possibly can question Pinecone with one extra metadata filter, “publish_year,” you probably have that metadata subject in your Pinecone data, which I extremely suggest creating.
Within the code, it’s a PUBLISH_YEAR_FILTER variable.
If in case you have publish_year metadata, you possibly can set the years as array values, and it’ll pull articles revealed within the specified years.
Generate Redirects Utilizing OpenAI’s Textual content Embeddings
Let’s do the identical process with OpenAI’s “text-embedding-ada-002” mannequin. The aim is to indicate the distinction in output from Google Vertex AI.
Merely create a brand new pocket book file in the identical listing, copy and paste this code, and run it.
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Non-obligatory, Checklist, Dict, Any
from openai import OpenAI
from pinecone import Pinecone, PineconeException
# Import tenacity for retry mechanism. Tenacity gives a decorator so as to add retry logic
# to capabilities, making them extra strong in opposition to transient errors like community points or API charge limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optionally available, preserve if operating in Jupyter)
from IPython.show import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Outline configurable parameters for the script. These might be simply adjusted
# with out modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the enter CSV file containing URLs to be redirected.
# Anticipated columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file the place the generated redirect map can be saved.
PINECONE_API_KEY = "YOUR_PINECONE_API_KEY" # Your API key for Pinecone. Substitute along with your precise key.
PINECONE_INDEX_NAME = "article-index-ada" # The identify of the Pinecone index the place article vectors are saved.
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY" # Your API key for OpenAI. Substitute along with your precise key.
OPENAI_EMBEDDING_MODEL_ID = "text-embedding-ada-002" # Identifier for the OpenAI textual content embedding mannequin to make use of.
CANDIDATE_FETCH_COUNT = 3 # Variety of potential redirect candidates to fetch from Pinecone for every enter URL.
TEST_MODE = True # If True, the script will course of solely a small subset of the enter knowledge (MAX_TEST_ROWS).
# Helpful for testing and debugging.
MAX_TEST_ROWS = 5 # Most variety of rows to course of when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to keep away from hitting charge limits).
PUBLISH_YEAR_FILTER: Checklist[int] = [] # Non-obligatory: Checklist of years to filter Pinecone outcomes by 'publish_year' metadata eg. [2024,2025].
# If empty, no 12 months filtering is utilized.
LOG_BATCH_SIZE = 5 # Variety of URLs to course of earlier than flushing the outcomes to the output CSV.
# This helps in saving progress incrementally and managing reminiscence.
MIN_SLUG_LENGTH = 3 # Minimal size for a URL slug phase to be thought-about significant for embedding.
# Shorter segments could be noise or much less descriptive.
# Retry configuration for API calls (OpenAI and Pinecone).
# These parameters management how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Most variety of instances to retry an API name earlier than giving up.
INITIAL_RETRY_DELAY = 1 # Preliminary delay in seconds earlier than the primary retry.
# Subsequent retries can have exponentially growing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
stage=logging.INFO, # Set the logging stage to INFO, that means INFO, WARNING, ERROR, CRITICAL messages can be proven.
format="%(asctime)s %(levelname)s %(message)s" # Outline the format of log messages (timestamp, stage, message).
)
# ─── INITIALIZE OPENAI CLIENT & PINECONE ───────────────────────────────────────
# Initialize the OpenAI shopper as soon as globally. This handles useful resource administration effectively
# because the shopper object manages connections and authentication.
shopper = OpenAI(api_key=OPENAI_API_KEY)
strive:
# Initialize the Pinecone shopper and connect with the required index.
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.data(f"Related to Pinecone index '{PINECONE_INDEX_NAME}'.")
besides PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a essential dependency for locating redirect candidates.
logging.error(f"Pinecone init error: {e}")
elevate
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical type by:
1. Stripping question strings (e.g., `?param=worth`) and URL fragments (e.g., `#part`).
2. Dealing with URL-encoded fragment markers (`%23`).
3. Preserving the trailing slash if it was current within the unique URL's path.
This ensures consistency with the unique website's URL construction.
Args:
url (str): The enter URL.
Returns:
str: The canonicalized URL.
"""
# Take away question parameters and URL fragments.
temp = url.break up('?', 1)[0]
temp = temp.break up('#', 1)[0]
# Verify for URL-encoded fragment markers and take away them.
enc_idx = temp.decrease().discover('%23')
if enc_idx != -1:
temp = temp[:enc_idx]
# Decide if the unique URL path ended with a trailing slash.
preserve_slash = temp.endswith('/')
# Strip trailing slash if not initially current.
if not preserve_slash:
temp = temp.rstrip('/')
return temp
def slug_from_url(url: str) -> str:
"""
Extracts and joins significant, non-numeric path segments from a canonical URL
to type a "slug" string. This slug can be utilized as textual content for embedding when
a URL's title just isn't accessible.
Args:
url (str): The enter URL.
Returns:
str: A hyphen-separated string of related slug elements.
"""
clear = canonical_url(url) # Get the canonical model of the URL.
path = urlparse(clear).path # Extract the trail element of the URL.
segments = [seg for seg in path.split('/') if seg] # Break up path into segments and take away empty ones.
# Filter segments primarily based on standards:
# - Not purely numeric (e.g., '123' is excluded).
# - Size is bigger than or equal to MIN_SLUG_LENGTH.
# - Comprises at the least one alphanumeric character (to exclude purely particular character segments).
elements = [seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'[A-Za-z0-9]', seg)]
return '-'.be a part of(elements) # Be part of the filtered elements with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for OpenAI API errors. This makes the embedding technology
# extra resilient to transient points like community issues or API charge limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
cease=stop_after_attempt(MAX_RETRIES), # Cease retrying after a most variety of makes an attempt.
retry=retry_if_exception_type(Exception), # Retry on any Exception from OpenAI shopper (might be refined to openai.APIError if desired).
reraise=True # Re-raise the exception if all retries fail, permitting the calling operate to deal with it.
)
def generate_embedding(textual content: str) -> Non-obligatory[List[float]]:
"""
Generate a vector embedding for the given textual content utilizing OpenAI's text-embedding-ada-002
by way of the globally initialized OpenAI shopper. Consists of retry logic for API calls.
Args:
textual content (str): The enter textual content (e.g., URL title or slug) to embed.
Returns:
Non-obligatory[List[float]]: A listing of floats representing the embedding vector,
or None if the enter textual content is empty/whitespace or
if an sudden error happens after retries.
"""
if not textual content or not textual content.strip():
# If the textual content is empty or solely whitespace, no embedding might be generated.
return None
strive:
resp = shopper.embeddings.create( # Use the globally initialized OpenAI shopper to get embeddings.
mannequin=OPENAI_EMBEDDING_MODEL_ID,
enter=textual content
)
return resp.knowledge[0].embedding # Return the embedding vector (record of floats).
besides Exception as e:
# Log a warning if an OpenAI error happens, then re-raise to set off the `tenacity` retry mechanism.
logging.warning(f"OpenAI embedding error (retrying): {e}")
elevate # The `reraise=True` within the decorator will catch this and retry.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an enter CSV, producing
embeddings, querying Pinecone for related articles, and figuring out
appropriate redirect candidates.
Args:
input_csv (str): Path to the enter CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Variety of candidates to fetch from Pinecone.
test_mode (bool): If True, course of solely a restricted variety of rows.
"""
# Learn the enter CSV file right into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that every one required columns are current within the DataFrame.
if not required.issubset(df.columns):
elevate ValueError(f"Enter CSV should have columns: {required}")
# Create a set of canonicalized enter URLs for environment friendly lookup.
# That is used to forestall an enter URL from redirecting to itself or one other enter URL,
# which may create redirect loops or redirect to a web page that can be being redirected.
input_urls = set(df["URL"].map(canonical_url))
start_idx = 0
# Implement resume performance: if the output CSV already exists,
# attempt to discover the final processed URL and resume from the following row.
if os.path.exists(output_csv):
strive:
prev = pd.read_csv(output_csv)
besides EmptyDataError:
# Deal with case the place the output CSV exists however is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the final URL that was processed and written to the output file.
final = prev["URL"].iloc[-1]
# Discover the index of this final URL within the unique enter DataFrame.
idxs = df.index[df["URL"].map(canonical_url) == final].tolist()
if idxs:
# Set the beginning index for processing to the row after the final processed URL.
start_idx = idxs[0] + 1
logging.data(f"Resuming from row {start_idx} after {final}.")
# Decide the vary of rows to course of primarily based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc[start_idx:end_idx] # Choose a slice of the DataFrame for testing.
logging.data(f"Take a look at mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc[start_idx:] # Course of all remaining rows.
logging.data(f"Processing rows {start_idx} to {len(df)-1}.")
whole = len(df_proc) # Complete variety of URLs to course of on this run.
processed = 0 # Counter for efficiently processed URLs.
batch: Checklist[Dict[str, Any]] = [] # Checklist to retailer outcomes earlier than flushing to CSV.
# Iterate over every row (URL) within the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row["URL"] # Unique URL from the enter CSV.
url = canonical_url(raw_url) # Canonicalized model of the URL.
# Get title and class, dealing with potential lacking values by defaulting to empty strings.
title = row["Title"] if isinstance(row["Title"], str) else ""
class = row["primary_category"] if isinstance(row["primary_category"], str) else ""
# Decide the textual content to make use of for producing the embedding.
# Prioritize the 'Title' if accessible, in any other case use a slug derived from the URL.
if title.strip():
textual content = title
else:
raw_slug = slug_from_url(raw_url)
if not raw_slug or len(raw_slug) Whereas the standard of the output could also be thought-about passable, it falls wanting the standard noticed with Google Vertex AI.
Beneath within the desk, you possibly can see the distinction in output high quality.
| URL | Google Vertex | Open AI |
| /what-is-eat/ | /google-eat/what-is-it/ | /5-things-you-can-do-right-now-to-improve-your-eat-for-google/408423/ |
| /local-seo-for-lawyers/ | /law-firm-seo/what-is-law-firm-seo/ | /legal-seo-conference-exclusively-for-lawyers-spa/528149/ |
In the case of search engine optimization, although Google Vertex AI is thrice dearer than OpenAI’s mannequin, I favor to make use of Vertex.
The standard of the outcomes is considerably greater. When you might incur a larger price per unit of textual content processed, you profit from the superior output high quality, which straight saves beneficial time on reviewing and validating the outcomes.
From my expertise, it prices about $0.04 to course of 20,000 URLs utilizing Google Vertex AI.
Whereas it’s mentioned to be dearer, it’s nonetheless ridiculously low cost, and also you shouldn’t fear for those who’re coping with duties involving a couple of thousand URLs.
Within the case of processing 1 million URLs, the projected value can be roughly $2.
Should you nonetheless desire a free technique, use BERT and Llama fashions from Hugging Face to generate vector embeddings with out paying a per-API-call charge.
The true price comes from the compute energy wanted to run the fashions, and it’s essential to generate vector embeddings of all of your articles in Pinecone or another vector database utilizing these fashions if you can be querying utilizing vectors generated from BERT or Llama.
In Abstract: AI Is Your Highly effective Ally
AI lets you scale your search engine optimization or advertising and marketing efforts and automate essentially the most tedious duties.
This doesn’t change your experience. It’s designed to stage up your expertise and equip you to face challenges with larger functionality, making the method extra participating and enjoyable.
Mastering these instruments is important for fulfillment. I’m obsessed with writing about this matter to assist newcomers study and really feel impressed.
As we transfer ahead on this collection, we’ll discover methods to use Google Vertex AI for constructing an inner linking WordPress plugin.
Extra Sources:
Featured Picture: BestForBest/Shutterstock
Source link