

















What Can You Do With This Plugin?
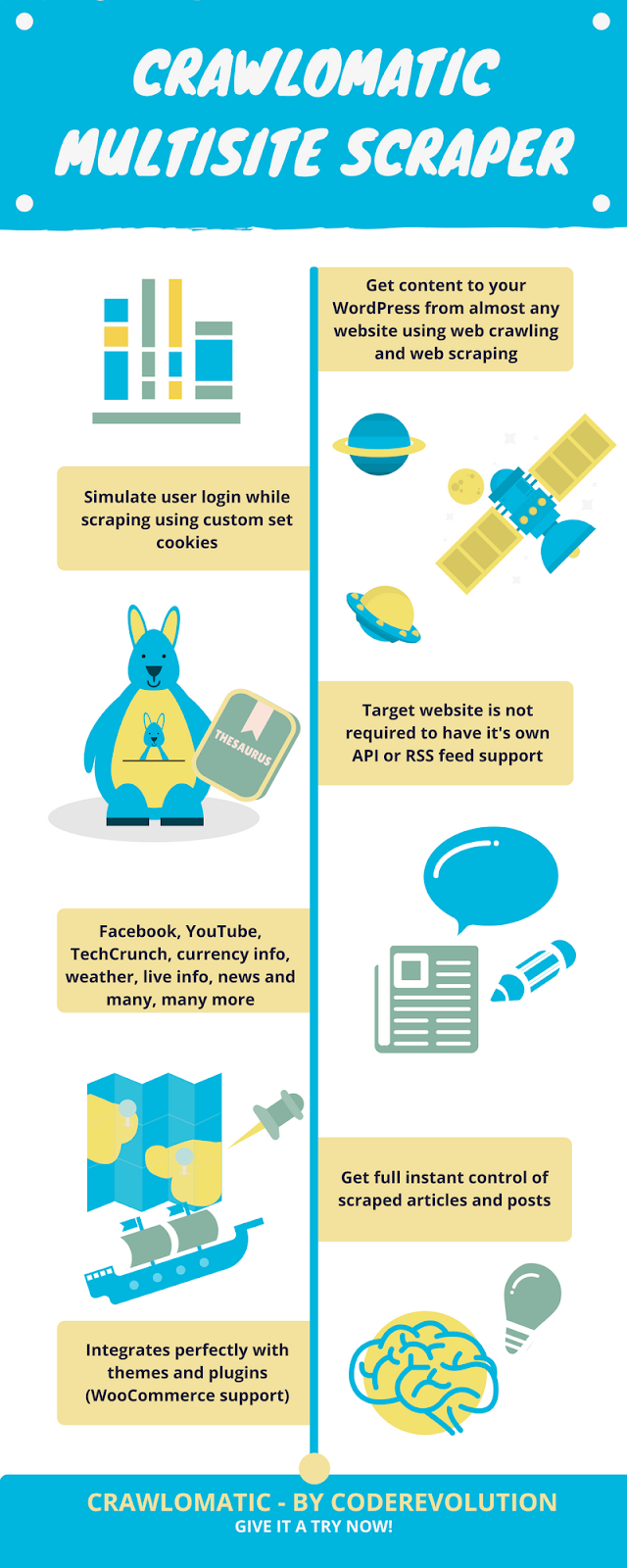
Crawlomatic Multisite Scraper Submit Generator Plugin for WordPress is a breaking edge web site crawling and scraping, publish generator autoblogging plugin that makes use of web site crawling and scraping to show your web site right into a autoblogging or perhaps a cash making machine!
Get content material from nearly any webpage! You now not want API’s which requires registration and gives restricted entry, additionally you’ll be able to retrieve information from non API offering web sites. Schedule it for as soon as and let it autopilot your posts 7/24 for you want a grasp!
How does it work?
This plugin will crawl the seed URL you give it (crawling means that it’ll search all hyperlinks that the webpage incorporates) and can go to and extract content material from every crawled URL. The crawling course of is customizable: you’ll be able to set the crawling depth, crawling charge, most crawled article depend, crawl solely hyperlinks with particular class or ID and lots of extra customizations.
Crawlomatic v2.0 replace
Within the v2.0 replace, a brand new stay scraper shortcode was added to the plugin: [crawlomatic-scraper]. This new characteristic makes this plugin a simple to implement internet information extractor for WordPress. Because of this, it may be used to show real-time information from any web sites straight into your posts, pages or sidebar. It additionally briefly caches the scraped content material, so your web site is not going to over use on assets. You should use this plugin to incorporate real-time inventory quotes, cricket or soccer scores or some other generic content material from public domains!
New options included on this replace:
- Scraped output will be displayed by means of customized template tag, shortcode in web page, publish and sidebar (by means of a textual content widget).
- Configurable caching of scraped information. Cache timeout will be outlined in minutes for each scraped information.
- Configurable Useragent on your scraper will be set for each scrape.
- Configurable default settings like enabling, useragent, timeout, caching, error dealing with.
- A number of methods to question content material – CSS Selector, XPath or Regex, Auto Detection.
- A variety of arguments for parsing content material.
- Choice to move publish arguments to a URL to be scraped.
- Dynamic conversion of scraped content material to specified character encoding to scrape information from a web site utilizing completely different charset.
- Create scraped pages on the fly utilizing dynamic technology of URLs to scrape or publish arguments primarily based in your web page’s get or publish arguments.
- Callback perform for superior parsing of scraped information.
Examine the official documentation of the v2 update, flick through examples and test FAQ for crafting a superbly optimized internet scraper.
Extra concerning the plugin
You may scrape content material from nearly each website online that you simply open in your browser. If the content material is loaded utilizing JavaScript, the plugin will be mixed with PhantomJS to scrape additionally JavaScript generated content material.
Additionally, you’ll be able to robotically generate limitless variety of customized web site crawling and scraping.
Different plugin options:
- v2.5.5 replace: Mechanically replace scraped posts/pages/merchandise if the supply web site modifications + unpublish (set as draft) the publish/web page/product if the scraped URL is now not obtainable on the supply web site (optionally available options, will be enabled/disabled)
- v2.5.1 replace: Scrape WooCommerce product variants from different WooCommerce/Shopify shops
- v2.5.0 replace: Scrape search engine outcomes on your customized key phrase searches, from Google or from Bing. Examine the tutorial video of this new feature.
- v2.4.1 replace: Scrape product picture galleries for WooCommerce merchandise (for non-product publish varieties, publish attachments might be created from the scraped photos)
- v2.3.5 replace: Execute your individual JavaScript code on the scraped HTML and scrape the outcomes – this characteristic is accessible solely when headless browsers are used for scraping (Puppeteer/Tor/PhantomJS) or HeadlessBrowserAPI
- v2.2.1 replace: Crawl RSS feeds for hyperlinks and scrape articles listed in them
- v2.2.0 replace: Use HeadlessBrowserAPI to scrape JavaScript Generated HTML Content material from any web site on the web with out the necessity to set up something (in addition to this plugin) in your server – tutorial video
- v2.1.0 replace: Scrape .onion web sites from the Darkish Net utilizing the Tor Browser and Puppeteer! – tutorial video
- v2.0.0 replace: Stay Scraper shortcode added for much more crawling management and scraping energy: [crawlomatic-scraper]
- v1.7.1 replace: Sitemap crawling supported – video tutorial
- v1.6.5 replace: Visible content material selector assist added – video tutorial
- v1.6.0 replace: Added the flexibility to make screenshots of crawled pages and use them in generated publish’s content material – video tutorial
- v1.5.2 replace: Capacity to shorten outgoing (publish supply) hyperlinks (and monetize them), utilizing Shorte.st hyperlink shortener service – example of shortened link
- v1.4.8 replace: Added JavaScript execution assist for crawled pages – requires PhantomJS put in on server – How to install PhantomJs? – video tutorial
- v1.4.4 replace: Added the flexibility to set a number of proxies for crawling pages. The plugin will choose one at random at every web page entry
- v1.4.0 replace: Added the flexibility to paginate crawling (crawling for articles will proceed on the subsequent web page of the seed web page).
- v1.4.0 replace: Added the flexibility to import product costs for crawled merchandise (WooCommerce suitable) + dropshipping value automated modification – video tutorial
- v1.4.0 replace: Added the flexibility to extend imported product value by a hard and fast quantity or to multiply it with a predefined quantity (nice worth for dropshipping!)
- v1.2.8 replace: Added paginated publish importing assist (right into a single crawled publish) Examine: VIDEO.
- v1.2.4 replace: Added the flexibility to set proxies for crawling pages
- v1.2.3 replace: Added an choice to crawl the web page from Google cache when direct crawling fails (blocked)
- Google Translate assist – choose the language during which you need to publish your articles
- Textual content Spinner assist – robotically modify generated textual content, altering phrases with their synonyms – built-in, The Finest Spinner, SpinRewriter, WordAI, TurkceSpin and others – nice search engine optimisation worth!
- customizable generated publish standing (revealed, draft, pending, non-public, trash)
- shortcode to listing all posts generated by this plugin: [crawlomatic-list-posts type => ‘any’, order => ‘ASC’, ‘orderby’ => ‘date’, ‘posts’ => 50, ‘category’ => ’’, ‘ruleid’ => ’’]
- crawling and scraping will be set to respect the robots.txt recordsdata of internet sites and robots HTML headers of scraped pages
- robotically generate publish classes or tags from market objects
- manually add publish classes or tags to objects
- select if you wish to replace publish whether it is already posted
- ship customized cookies with the request to the crawled webpage (authentification)
- generate publish or web page or any customized publish sort
- embeds movies from YouTube, Vimeo, Flickr, IGN, Ustream.television and DailyMotion utilizing web site crawling and scraping
- outline publishing constrains: don’t publish posts that shouldn’t have photos, posts with brief/lengthy title/content material
- robotically generate a featured picture for the publish
- allow/disable feedback, pingbacks or trackbacks for the generated publish
- customise publish title and content material (with the included huge number of related publish shortcodes)
- ‘Key phrase Replacer Instrument’ – It’s function is to outline key phrases which can be substituted robotically along with your affiliate hyperlinks, wherever they seem within the content material of your web site. For instance, you’ll be able to outline a key phrase ‘codecanyon’ and have it substituted by a hyperlink to http://www.codecanyon.net/?ref=user_name wherever it seems in your web site’s content material.
- ‘Random Sentence Generator Instrument’ (related sentences – as you outline them)
- choice to robotically delete generated posts after a time frame
- detailed plugin exercise logging
- scheduled rule runs
- customized subject assist for generated posts
- customized taxonomies assist for generated posts
- limitless crawled variable importing (limitless imported components of the crawled pages)
- possibility to repeat or not photos domestically
- potential to parse JSON information utilizing Regex
- possibility so as to add canonical meta tag to generated posts
- Most/minimal title size publish limitation
- Most/minimal content material size publish limitation
- Add publish provided that predefined required key phrases present in title/content material
- Add publish provided that predefined banned key phrases will not be discovered within the title/content material
- Save and restore plugin rule listing from file

Testing this plugin
- You may take a look at the plugin’s performance utilizing the ‘Test Site Generator’. Right here you’ll be able to attempt the plugin’s full performance. Be aware that the generated testing weblog might be deleted robotically after 24 hours.
Plugin Necessities
- PHP DOM -> learn how to set up it (when you don’t have it, however most likely you have already got it): http://php.net/manual/en/dom.setup.php
- PHP 5.0 or greater
- dom, mbstring, iconv and json extensions (enabled by default)

For more information on learn how to configure the plugin, please test additionally this 1 hour long tutorial video, which covers the total characteristic set of the plugin.


Want assist?
Please test our knowledge base, it might have the reply to your query or an answer on your concern. If not, simply electronic mail me at [email protected] and I’ll reply as quickly as I can.









Changelog:
Model 1.0 Launch Date 2017-08-15
First model launched!
Model 1.1 Launch Date 2017-08-16
Fastened some small points
Model 1.2 Launch Date 2017-08-17
Added the flexibility to crawl web page by div class or id
Model 1.2.1 Launch Date 2017-08-18
Fastened incompatibility with some WordPress installs
Model 1.2.2 Launch Date 2017-08-22
Added a shortcode to show publish generated by this plugin
Model 1.2.3 Launch Date 2017-08-30
Added an choice to crawl the web page from Google cache when direct crawling fails (blocked)
Model 1.2.4 Launch Date 2017-08-31
Added the flexibility to set proxies for crawling pages
Model 1.2.5 Launch Date 2017-09-04
Added the canonicalization for generated articles
Model 1.2.6 Launch Date 2017-09-13
Made the plugin timezone conscious
Model 1.2.7 Launch Date 2017-09-14
Fastened publish date for non gmt blogs
Model 1.2.8 Launch Date 2017-09-23
Added paginated publish importing assist
Model 1.2.9 Launch Date 2017-09-27
Bugfixes
Model 1.3.0 Launch Date 2017-09-28
Fastened rule restore
Model 1.3.1 Launch Date 2017-10-20
Fastened featured picture technology
Model 1.3.2 Launch Date 2017-10-22
Added crawling helper
Model 1.3.3 Launch Date 2017-11-06
Fastened a reminiscence concern
Model 1.3.4 Launch Date 2017-11-07
Bugfixes
Model 1.3.5 Launch Date 2017-12-14
Fastened class selector not working in all circumstances
Model 1.3.6 Launch Date 2017-12-18
Added the flexibility to specify a customized consumer agent for every crawled webpage
Model 1.3.7 Launch Date 2018-01-20
Added a brand new textual content spinner service: Spinrewriter
Model 1.3.8 Launch Date 2018-01-22
Plugin can now repeatedly import content material
Model 1.3.9 Launch Date 2018-02-02
Fastened concern when a number of crawl lessons the place specified
Model 1.4.0 Launch Date 2018-02-22
Main replace: added the flexibility to crawl imported product costs (WooCommerce suitable) Added the flexibility to crawl serial content material (paged crawling - crawling for articles will proceed on the subsequent web page)
Model 1.4.1 Launch Date 2018-03-07
Bugfixes
Model 1.4.2 Launch Date 2018-03-21
Fastened a replica posting concern
Model 1.4.3 Launch Date 2018-03-22
Fastened a crucial concern with a number of rule working
Model 1.4.4 Launch Date 2018-04-04
Added the flexibility to outline a number of proxies. The plugin will choose one at random at every web page entry
Model 1.4.5 Launch Date 2018-07-13
Up to date built-in readability module
Model 1.4.6 Launch Date 2018-07-16
Crucial bugfixes
Model 1.4.7 Launch Date 2018-07-19
Added the flexibility to not translate hyperlinks
Model 1.4.8 Launch Date 2018-09-05
Added JavaScript execution assist for crawled pages - requires PhantomJS put in on server
Model 1.4.9 Launch Date 2018-09-18
Bugfixes
Model 1.5.0 Launch Date 2018-09-24
Added the flexibility so as to add customized publish taxonomies from crawled content material Added the flexibility so as to add limitless crawled variables to posts's content material/ meta/ taxonomies
Model 1.5.1 Launch Date 2018-10-16
Fastened concern when importing massive pages
Model 1.5.2 Launch Date 2018-10-24
Added the flexibility to shorten hyperlinks utilizing Shorte.st
Model 1.5.3 Launch Date 2018-10-29
Fastened concern when importing paginated posts
Model 1.5.4 Launch Date 2018-11-06
Added the flexibility to strip HTML components by tag title (div,a,span,and many others.)
Model 1.5.5 Launch Date 2018-11-07
Added WooCommerce product class creation assist
Model 1.5.6 Launch Date 2018-12-16
Added nested importing assist - import blended content material right into a single publish, from a number of plugins created by CodeRevolution
Model 1.5.7 Launch Date 2018-12-16
Added the flexibility to outline a listing of URLs to skip from crawling and importing
Model 1.5.8 Launch Date 2019-01-08
Added the flexibility to import royalty free photos for created posts
Model 1.5.9 Launch Date 2019-01-12
Added Gutenberg blocks assist
Model 1.6.0 Launch Date 2019-02-01
Added the flexibility to make screenshots of scraped pages
Model 1.6.1 Launch Date 2019-02-06
Improved compatibility with some crawled pages
Model 1.6.2 Launch Date 2019-04-19
Safety replace
Model 1.6.3 Launch Date 2019-05-15
Fastened some just lately discovered bugs with publish pagination
Model 1.6.4 Launch Date 2019-05-17
Added assist for TurkceSpin content material spinner
Model 1.6.5 Launch Date 2019-05-27
Added a a lot demanded new characteristic: Visible Content material Selector for assigning scraped web page content material Added the flexibility to scrape pages from backside to high Added the flexibility to exchange phrases in scraped content material Different minor bug fixes and performance enhancements
Model 1.6.6 Launch Date 2019-07-26
Fastened timeout concern with some crawled pages Many small points mounted and options improved
Model 1.6.7 Launch Date 2019-08-05
Fastened concern with Google Translate
Model 1.6.8 Launch Date 2019-11-15
WordPress 5.3 compatibility replace
Model 1.6.9 Launch Date 2020-05-11
New options added for content material templates Bugfix replace
Model 1.7.0 Launch Date 2020-07-21
Added assist for scraping extra websites
Model 1.7.1 Launch Date 2020-09-28
Added the flexibility to crawl sitemaps and to scrape posts linked in them Added the flexibility to respect the directives set within the robots.txt recordsdata
Model 2.0.0 Launch Date 2020-12-08
Added a brand new shortcode and Gutenberg block various that may allow stay scraping of any web site Main efficiency enchancment Fastened reported bugs
Model 2.1.0 Launch Date 2021-01-02
Added assist for utilizing the Tor Browser to crawl darkish web pages! Scrape .onion web sites such as you would scrape some other public web site!
Model 2.1.1 Launch Date 2021-01-04
Added the flexibility to crawl and scrape pages utilizing POST requests (POST kind submission scraping assist)
Model 2.2.0 Launch Date 2021-01-14
Added assist for HeadlessBrowserAPI to scrape JavaScript rendered content material with ease
Model 2.2.1 Launch Date 2021-01-16
PHP 8 compatibility replace Added assist for crawling hyperlinks from RSS feeds
Model 2.2.2 Launch Date 2021-01-28
Fastened uncommon concern when saving importing rule settings on some PHP 8 configurations
Model 2.2.3 Launch Date 2021-02-01
Improved content material extraction algorithm
Model 2.2.4 Launch Date 2021-02-17
Added the flexibility to not spin posts generated by particular guidelines
Model 2.2.5 Launch Date 2021-03-07
Added the flexibility to enter a number of URLs (one per line) to be crawled and scraped
Model 2.2.6 Launch Date 2021-03-07
Visible Selector enhancements - now will probably be ready to make use of HeadlessBrowserAPI/Puppeteer/PhantomJS/Tor to visualise scrape content material
Model 2.2.7 Launch Date 2021-04-02
Fastened uncommon points when crawling hyperlinks with URL parameters
Model 2.2.8 Launch Date 2021-04-07
Fastened uncommon points with relative URL paths in crawled content material
Model 2.2.9 Launch Date 2021-05-03
Added the flexibility to skip publishing of latest posts if not photos discovered (individually, for every rule)
Model 2.3.0 Launch Date 2021-05-19
Added the flexibility to make screenshots of internet sites utilizing the HeadlessBrowserAPI characteristic
Model 2.3.1 Launch Date 2021-06-10
Fastened content material extracting/stripping in case of some web sites with dynamically generated content material
Model 2.3.2 Launch Date 2021-07-15
Added a number of Regex expression assist (for content material stripping and substitute)
Model 2.3.3 Launch Date 2021-07-18
Added SpinnerChief to the supported premium textual content spinners (SpinRewriter, The Finest Spinner, WordAI, TurkceSpin)
Model 2.3.4 Launch Date 2021-07-19
Added Bing Translator assist (subsequent to Google Translator and DeepL Translator)
Model 2.3.5 Launch Date 2021-08-06
Added the flexibility to execute your individual customized JavaScript on scraped pages when utilizing headless browsers (PhantomJS/Puppeteer/Tor) or HeadlessBrowserAPI (XSS - cross web site scripting characteristic) and scrape the ensuing HTML content material
Model 2.3.6 Launch Date 2021-08-30
Added the flexibility to set featured photos of posts from web site screenshots Added the flexibility to take away HTML content material (go away textual content solely) of XPath matched content material
Model 2.3.7 Launch Date 2021-09-02
Added the flexibility to set native storage objects when scraping web sites (these are just like cookies, their utilization is supported solely when utilizing headless browsers or HeadlessBrowserAPI at the side of the plugin)
Model 2.3.8 Launch Date 2021-09-15
Added the flexibility to set the WPML language to created posts
Model 2.3.9 Launch Date 2021-10-19
WooCommerce product scraping associated enhancements
Model 2.4.0 Launch Date 2022-02-28
Added assist for creating WooCommerce product attributes and assign values to them from scraped information
Model 2.4.1 Launch Date 2022-03-05
Added the flexibility to scrape picture galleries for WooCommerce merchandise
Model 2.4.1.1 Launch Date 2022-03-21
Bugfix replace
Model 2.4.2 Launch Date 2022-04-20
Fastened Google Translator drawback attributable to a current Google API replace
Model 2.5.0 Launch Date 2022-05-01
Crawlomatic now can scrape search engine outcomes from Google and Bing - tutorial video: https://www.youtube.com/watch?v=h6fQeH9-X8c
Model 2.5.1 Launch Date 2022-05-06
Added the flexibility to scrape WooCommerce product variations from Shopify and different WooCommerce merchandise Added the flexibility to robotically detect product costs Improved readability module Fixes and enhancements
Model 2.5.2 Launch Date 2022-06-14
Added the flexibility to translate posts a 3rd time (performing like a Phrase Spinner, if the content material is translated again to the unique language
Model 2.5.3 Launch Date 2022-06-23
Fastened WooCommerce value scraping associated concern
Model 2.5.4 Launch Date 2022-09-12
Added the flexibility to scrape hyperlinks from TXT recordsdata
Model 2.5.5 Launch Date 2022-10-14
Main replace: publish/web page/product automated updating if the scraped supply URL modified
Model 2.5.6 Launch Date 2022-11-30
Main replace: added assist for Google Information scraping
Model 2.5.7 Launch Date 2023-01-05
Added a brand new potential to HeadlessBrowserAPI to click on on HTML components by CSS selectors, enabling loading of Ajax content material and bypassing Captchas which require a click on
Model 2.5.8 Launch Date 2023-01-17
Added product common value scraping characteristic to WooCommerce merchandise - the common value is the value displayed earlier than the low cost is utilized. You may scrape this full value from the web sites or add/multiply the unique value to create it robotically
Model 2.5.9 Launch Date 2023-02-10
Fastened Google Information scraping after current modifications
Model 2.6.0 Launch Date 2023-03-13
Added extra DeepL languages Multiline scraping expressions assist added Fastened all reported points
Model 2.6.0.1 Launch Date 2023-04-13
Fastened reported bugs
Model 2.6.0.2 Launch Date 2023-05-10
Improved scraper auto detection
Model 2.6.0.3 Launch Date 2023-05-22
Fastened extra reported bugs
Model 2.6.0.4 Launch Date 2023-06-13
Reworked backend, improved scraping velocity
Model 2.6.0.5 Launch Date 2023-06-29
Scraped content material now higher matches supply web site styling
Model 2.6.0.6 Launch Date 2023-07-28
Fastened Google Translate integration, working with newest modifications
Model 2.6.0.7 Launch Date 2023-10-18
Fastened PHP 8.2 associated errors
Model 2.6.1 Launch Date 2024-02-15
Fastened a problem with rule saving
Model 2.6.2 Launch Date 2024-03-15
Visible selector repair for CSS concern occurring in some circumstances
Model 2.6.3 Launch Date 2024-07-12
Bugfix launch Buy code verification now required for the plugin to perform
Model 2.6.4 Launch Date 2024-10-26
Content material filtering enhancements
Model 2.6.5 Launch Date 2024-10-31
Added assist for automated Magento product variation scraping
Model 2.6.6 Launch Date 2024-12-26
The plugin will detect if the identical picture was scraped earlier than to the media library and won't scrape the identical picture twice, however will reuse the present media library ID
Model 2.6.7 Launch Date 2025-03-28
Fastened reported points
Are you already a buyer?
In the event you already purchased this and you’ve got tried it out, please contact me within the merchandise’s remark part and provides me suggestions, so I could make it a greater WordPress plugin!
WordPress 6.8 and PHP 8.4 Examined!




Disclaimer
By way of this plugin you’ll be able to seize content material from varied web sites that doesn’t crucial belong to you or which aren’t beneath your management. In the event you seize copyrighted materials with out the writer’s permission, the plugin’s developer doesn’t assume any duty on your actions. Additionally, the plugin’s developer has no management over the character, content material and availability of these websites.


Do you want our work and wish extra of it?
Try this MEGA plugin bundle.

{kind=link}