


{kind=link}
In the summertime of 2017, a bunch of Google Mind researchers quietly printed a paper that will endlessly change the trajectory of synthetic intelligence. Titled “Attention Is All You Need,” this tutorial publication did not arrive with splashy keynotes or frontpage information. As a substitute, it debuted on the Neural Data Processing Methods (NeurIPS) convention, a technical gathering the place cutting-edge concepts typically simmer for years earlier than they attain the mainstream.
Few exterior the AI analysis neighborhood knew it on the time, however this paper would lay the groundwork for practically each main generative AI mannequin you have heard of right this moment from OpenAI’s GPT to Meta’s LLaMA variants, BERT, Claude, Bard, you identify it.
The Transformer is an progressive neural community structure that sweeps away the previous assumptions of sequence processing. As a substitute of linear, step-by-step processing, the Transformer embraces a parallelizable mechanism, anchored in a method often called self-attention. Over a matter of months, the Transformer revolutionized how machines perceive language.

A New Mannequin
Earlier than the Transformer, state-of-the-art pure language processing (NLP) hinged closely on recurrent neural networks (RNNs) and their refinements – LSTMs (Lengthy Quick-Time period Reminiscence networks) and GRUs (Gated Recurrent Models). These recurrent neural networks processed textual content word-by-word (or token-by-token), passing alongside a hidden state that was meant to encode the whole lot learn to this point.
This course of felt intuitive… in spite of everything, we learn language from left to proper, so why should not a mannequin?
However these older architectures got here with important shortcomings. For one, they struggled with very lengthy sentences. By the point an LSTM reached the tip of a paragraph, the context from the start typically felt like a light reminiscence. Parallelization was additionally troublesome as a result of every step relied on the earlier one. The sector desperately wanted a strategy to course of sequences with out being caught in a linear rut.
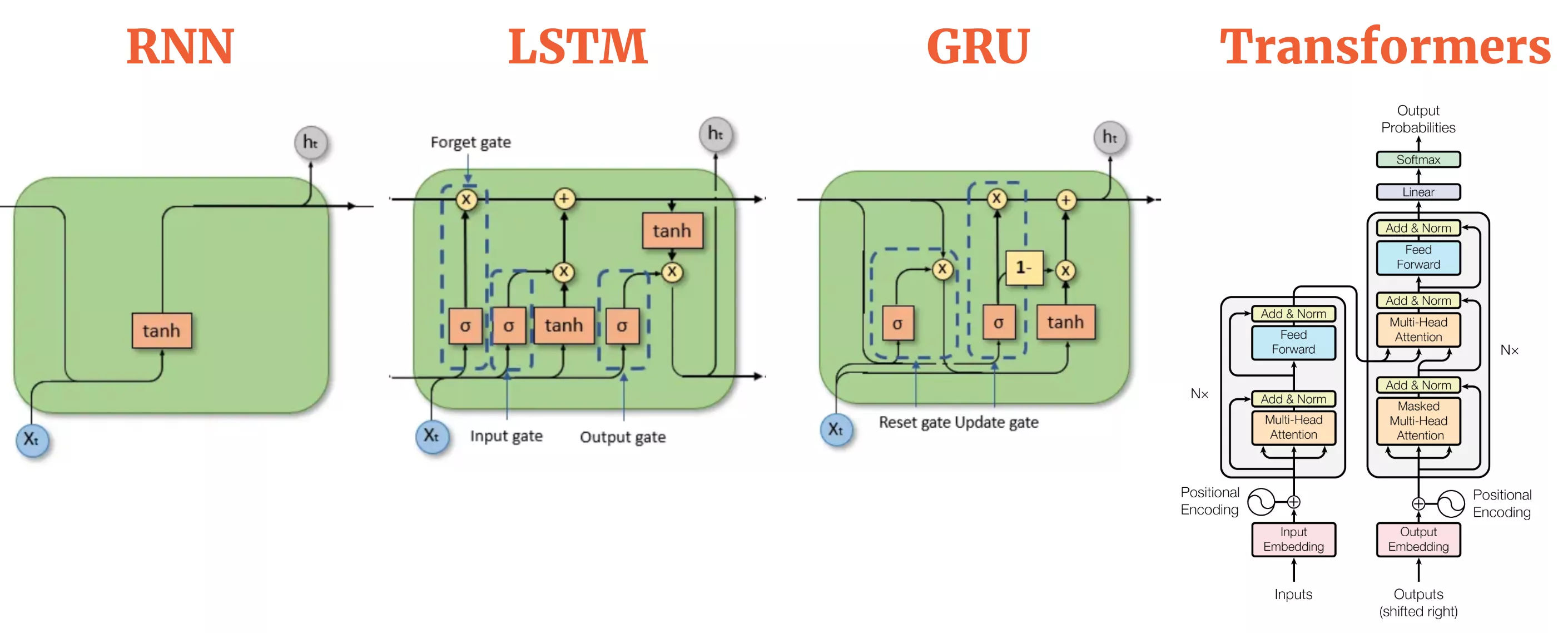
Google Mind researchers got down to change that dynamic. Their resolution was deceptively easy: ditch recurrence altogether. As a substitute, they designed a mannequin that might take a look at each phrase in a sentence concurrently and work out how every phrase associated to each different phrase.
This intelligent trick – known as the “consideration mechanism” – let the mannequin give attention to essentially the most related components of a sentence with out the computational baggage of recurrence. The outcome was the Transformer: quick, parallelizable, and bizarrely good at dealing with context over lengthy stretches of textual content.
The breakthrough thought was that “consideration,” not sequential reminiscence, might be the true engine of understanding language. Consideration mechanisms had existed in earlier fashions, however the Transformer elevated consideration from a supporting position to the star of the present. With out the Transformer’s full-attention framework, generative AI as we all know it could doubtless nonetheless be caught in slower, extra restricted paradigms.

However how did this concept come about at Google Mind? The backstory is sprinkled with the form of serendipity and mental cross-pollination that defines AI analysis. Insiders speak about casual brainstorming classes, the place researchers from totally different groups in contrast notes on how consideration mechanisms have been serving to clear up translation duties or enhance alignment between supply and goal sentences.
There have been coffee-room debates over whether or not the need of recurrence was only a relic of previous pondering. Some researchers recall “hall teaching classes” the place a then-radical thought – eradicating RNNs totally – was floated, challenged, and refined earlier than the group lastly determined to commit it to code.
A part of the brilliance of the transformer is that it made it attainable to coach on enormous datasets in a short time and effectively.
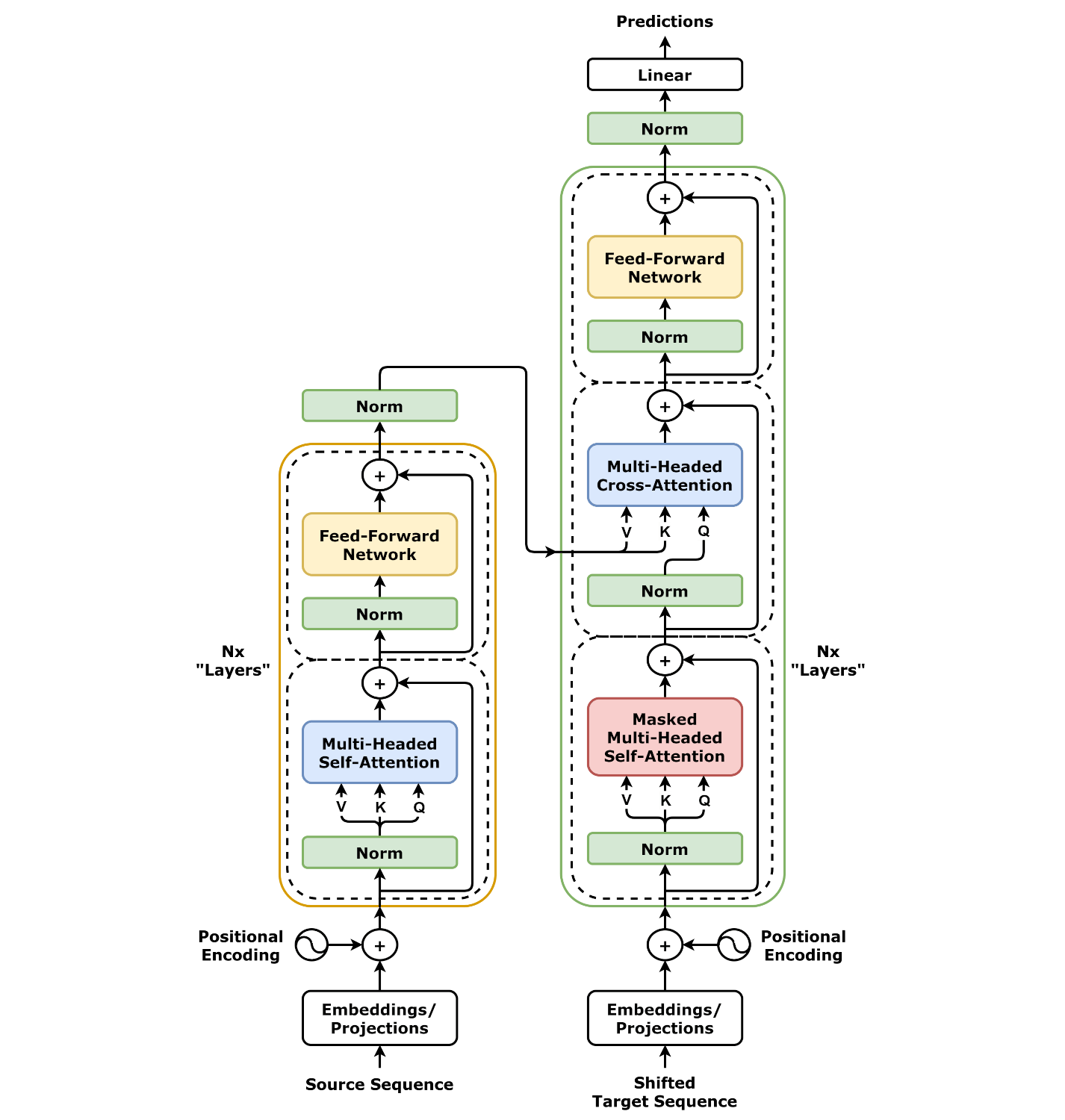
The Transformer’s structure makes use of two important components: an encoder and a decoder. The encoder processes the enter information and creates an in depth, significant illustration of that information utilizing layers of self-attention and easy neural networks. The decoder works equally however focuses on the beforehand generated output (like in textual content era) whereas additionally utilizing info from the encoder.
{kind=link}
A part of the brilliance of this design is that it made it attainable to coach on enormous datasets in a short time and effectively. An oft-repeated anecdote from the early days of the Transformer’s improvement is that some Google engineers did not initially understand the extent of the mannequin’s potential.
They knew it was good – significantly better than earlier RNN-based fashions at sure language duties – however the concept this might revolutionize the whole discipline of AI was nonetheless unfolding. It wasn’t till the structure was publicly launched and fanatics worldwide started experimenting that the true energy of the Transformer grew to become simple.
A Renaissance in Language Fashions
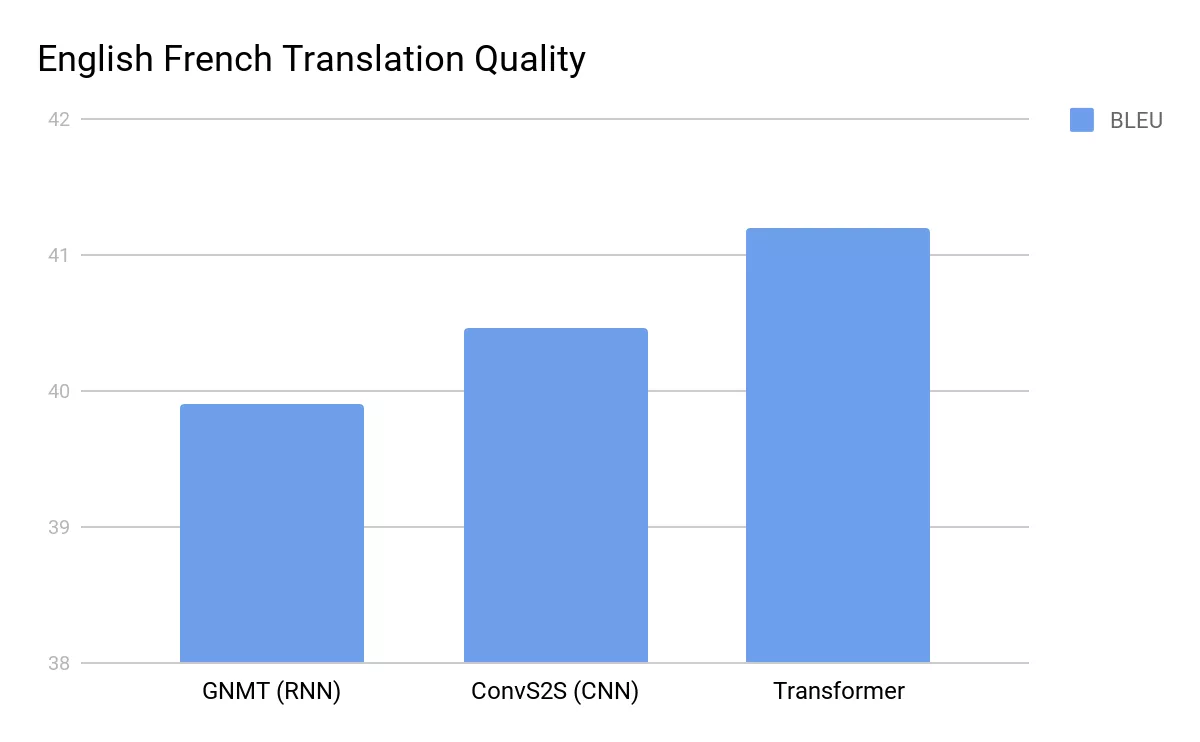
When Google Mind printed the 2017 paper, the NLP neighborhood reacted first with curiosity, then with astonishment. The Transformer structure was seen outperforming the most effective machine translation fashions at duties just like the WMT English-to-German and English-to-French benchmarks. However it wasn’t simply the efficiency – researchers shortly realized the Transformer was orders of magnitude extra parallelizable. Coaching instances plummeted. Out of the blue, duties that after took days or even weeks might be performed in a fraction of the time on the identical {hardware}.

Inside a 12 months of its introduction, the Transformer mannequin had impressed a wave of improvements. Google itself leveraged the Transformer structure to create BERT (Bidirectional Encoder Representations from Transformers). BERT drastically improved the best way machines understood language, taking the highest spot on many NLP benchmarks. It quickly discovered its approach into on a regular basis merchandise like Google Search, quietly enhancing how queries have been interpreted.
Media retailers found GPT’s prowess and showcased numerous examples – generally jaw-dropping, generally hilariously off-base.
Virtually concurrently, OpenAI took the Transformer blueprint and went in one other route with GPT (Generative Pre-trained Transformers).
GPT-1 and GPT-2 hinted on the energy of scaling. By GPT-3, it grew to become not possible to disregard how good these methods have been at producing human-like textual content and reasoning by means of advanced prompts.
The first ChatGPT version (late 2022) used an extra refined GPT-3.5 mannequin, it was a watershed second. ChatGPT might generate eerily coherent textual content, translate languages, write code snippets, and even produce poetry. Out of the blue, a machine’s capacity to supply human-like textual content was not a pipe dream however a tangible reality.

Media retailers found GPT’s prowess and showcased numerous examples – generally jaw-dropping, generally hilariously off-base. The general public was each thrilled and unnerved. The concept of AI-assisted creativity moved from science fiction to on a regular basis dialog. This wave of progress – fueled by the Transformer – reworked AI from a specialised instrument right into a general-purpose reasoning engine.
However the Transformer is not simply good at textual content. Researchers discovered that spotlight mechanisms might work throughout several types of information – pictures, music, code.
However the Transformer is not simply good at textual content. Researchers discovered that spotlight mechanisms might work throughout several types of information – pictures, music, code. Earlier than lengthy, fashions like CLIP and DALL-E have been mixing textual and visible understanding, producing “distinctive” artwork or labeling pictures with uncanny accuracy. Video understanding, speech recognition, and even scientific information evaluation started to learn from this similar underlying blueprint.
As well as, software program frameworks like TensorFlow and PyTorch included Transformer-friendly constructing blocks, making it simpler for hobbyists, startups, and trade labs to experiment. At present, it is not unusual to see specialised variants of the Transformer structure pop up in the whole lot from biomedical analysis to monetary forecasting.
The Race to Larger Fashions
A key discovery that emerged as researchers continued to push Transformers was the idea of scaling legal guidelines. Experiments by OpenAI and DeepMind discovered that as you enhance the variety of parameters in a Transformer and the scale of its coaching dataset, efficiency continues to enhance in a predictable method. This linearity grew to become an invite for an arms race of types: larger fashions, extra information, extra GPUs.
Experiments discovered that as you enhance the variety of parameters in a Transformer and the scale of its coaching dataset, efficiency continues to enhance in a predictable method… this linearity grew to become an invite for an arms race of types: larger fashions, extra information, extra GPUs.
Google, OpenAI, Microsoft, and lots of others have poured immense sources into constructing colossal Transformer-based fashions. GPT-3 was adopted by even bigger GPT-4, whereas Google launched fashions like PaLM with lots of of billions of parameters. Though these gargantuan fashions produce extra fluent and educated outputs, additionally they elevate new questions on price, effectivity, and sustainability.

Coaching such fashions consumes monumental computing energy (Nvidia is too happy about that one) and electrical energy – reworking AI analysis into an endeavor that’s a lot nearer right this moment to industrial engineering than the educational tinkering it as soon as was.
Consideration All over the place
ChatGPT has change into a cultural phenomenon, breaking out of tech circles and trade discussions to spark dinner desk conversations about AI-generated content material. Even individuals who aren’t tech-savvy now have some consciousness that “there’s this AI that may write this for me” or speak to me “like a human.” In the meantime, highschool students are increasingly turning to GPT queries as a substitute of Google or Wikipedia for solutions.
However all technological revolutions include unwanted side effects, and the Transformer’s affect on generative AI isn’t any exception. Even at this early stage, GenAI fashions have ushered in a brand new period of artificial media, elevating tough questions on copyright, misinformation, impersonations of public figures, and moral deployment.
The identical Transformer fashions that may generate convincingly human prose may produce misinformation and poisonous outputs. Biases can and can be current within the coaching information, which may be subtly embedded and amplified within the responses provided by GenAI fashions. In consequence, governments and regulatory our bodies are starting to pay shut consideration. How can we guarantee these fashions do not change into engines of disinformation? How can we defend mental property when fashions can produce textual content and pictures on demand?
Researchers and the businesses creating right this moment’s dominant fashions have began to combine equity checks, set up guardrails, and prioritize the accountable deployment of generative AI (or so they are saying). Nonetheless, these efforts are unfolding in a murky panorama, as important questions stay about how these fashions are skilled and the place large tech corporations supply their coaching information.
The “Consideration Is All You Want” paper stays a testomony to how open analysis can drive world innovation. By publishing all the important thing particulars, the paper allowed anybody – competitor or collaborator – to construct on its concepts. That spirit of openness by Google’s group, fueled the astonishing velocity at which the Transformer structure has unfold throughout the trade.
We’re solely starting to see what occurs as these fashions change into extra specialised, extra environment friendly, and extra extensively accessible. The machine studying neighborhood was in dire want for a mannequin that might deal with complexity at scale, and self-attention to this point has delivered. From machine translation to chatbots that may keep it up various conversations, from picture classification to code era. Transformers have change into the default spine for pure language processing after which some. However researchers are nonetheless questioning: is consideration really all we’d like?

New architectures are already rising, corresponding to Performer, Longformer, and Reformer, aiming to enhance the effectivity of consideration for very lengthy sequences. Others are experimenting with hybrid approaches, combining Transformer blocks with different specialised layers. The sector is something however stagnant.
Shifting ahead, every new proposal will garner scrutiny, pleasure, and why not, worry.
Maintain Studying. Explainers and Tech Culture options at TechSpot
Source link