


{kind=link}
![]()
When Apache Spark grew to become a top-level venture in 2014, and shortly thereafter burst onto the large knowledge scene, it together with the general public cloud disrupted the large knowledge market. Databricks Inc. cleverly optimized its tech stack for Spark and took benefit of the cloud to ship a managed service that has change into a number one synthetic intelligence and knowledge platform amongst knowledge scientists and knowledge engineers.
Nonetheless, rising buyer knowledge necessities and market forces are conspiring in a method that we imagine will trigger fashionable knowledge platform gamers typically and Databricks particularly to make some key directional selections and maybe even reinvent themselves.
On this Breaking Evaluation, we do a deeper dive into Databricks. We discover its present spectacular market momentum utilizing Enterprise Know-how Analysis survey knowledge. We’ll additionally lay out how buyer knowledge necessities are altering and what we expect the best knowledge platform will appear like within the mid-term. We’ll then consider core components of the Databricks portfolio towards that future imaginative and prescient and shut with some strategic selections we imagine the corporate and its prospects face.
To take action, we welcome in our good good friend George Gilbert, former equities analyst, market analyst and principal at Tech Alpha Companions.
Databricks’ present momentum is spectacular
Let’s begin by looking at buyer sentiment on Databricks relative to different rising firms.
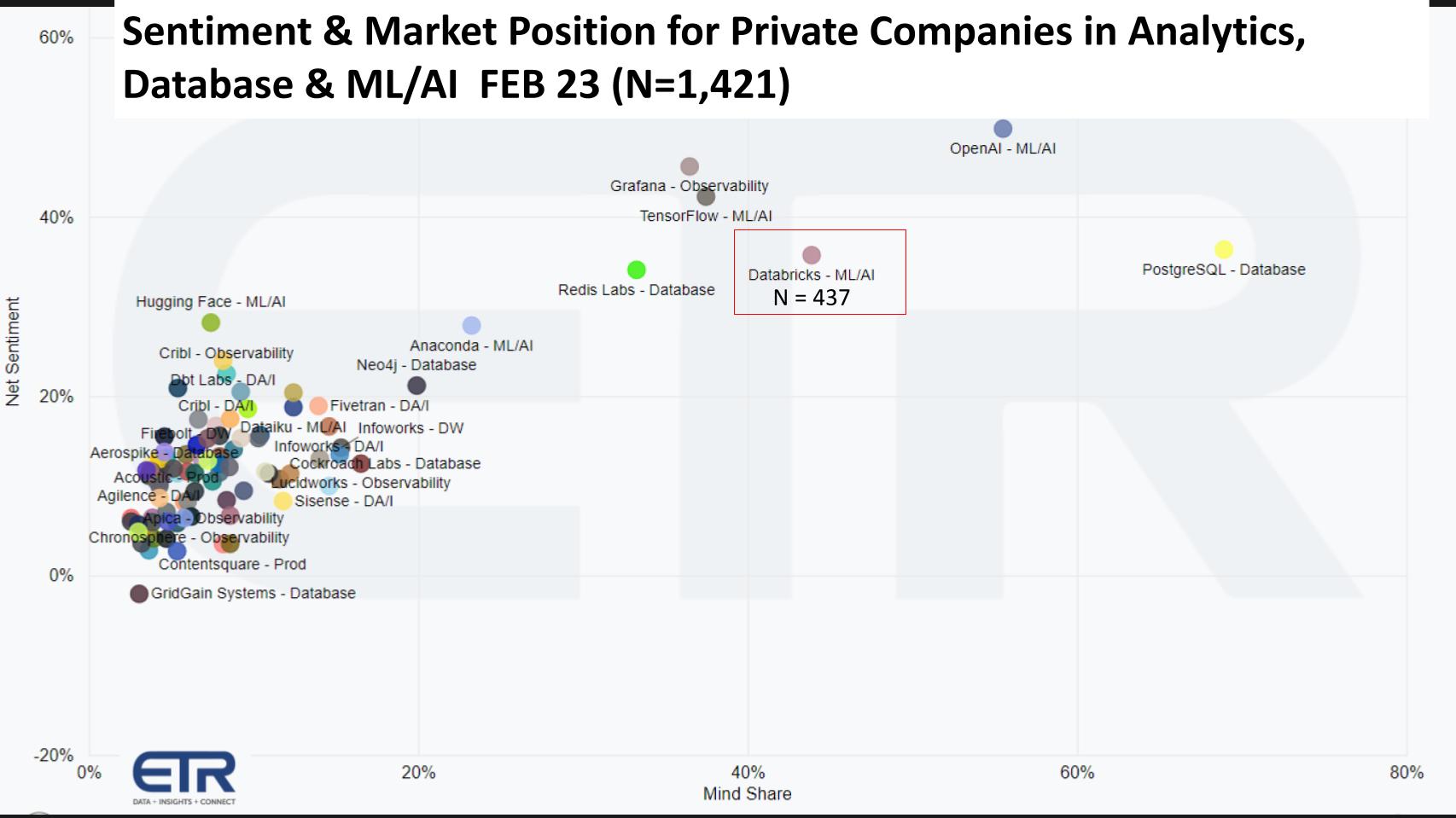
The chart above exhibits knowledge from ETR’s Rising Know-how Survey of personal expertise firms (N=1,421). We reduce the info on the analytics, database and ML/AI sectors. The vertical axis is a measure of buyer sentiment, which evaluates an data expertise choice maker’s consciousness of a agency and the probability of evaluating, intent to buy or present adoption. The horizontal axis exhibits mindshare within the knowledge set based mostly on Ns. We’ve bordered Databricks with a purple define. The corporate has been a constant excessive performer on this survey. We’ve previously reported that OpenAI LLC, which got here on the scene this previous quarter, leads all names, however Databricks is outstanding, established and transacting offers, whereas OpenAI is a buzz machine proper now. Word as nicely, ETR exhibits some open-source instruments only for reference. However so far as corporations go, Databricks is main and impressively positioned.
Evaluating Databricks, Snowflake, Cloudera and Oracle
Now let’s see how Databricks stacks as much as some mainstream cohorts within the knowledge house.
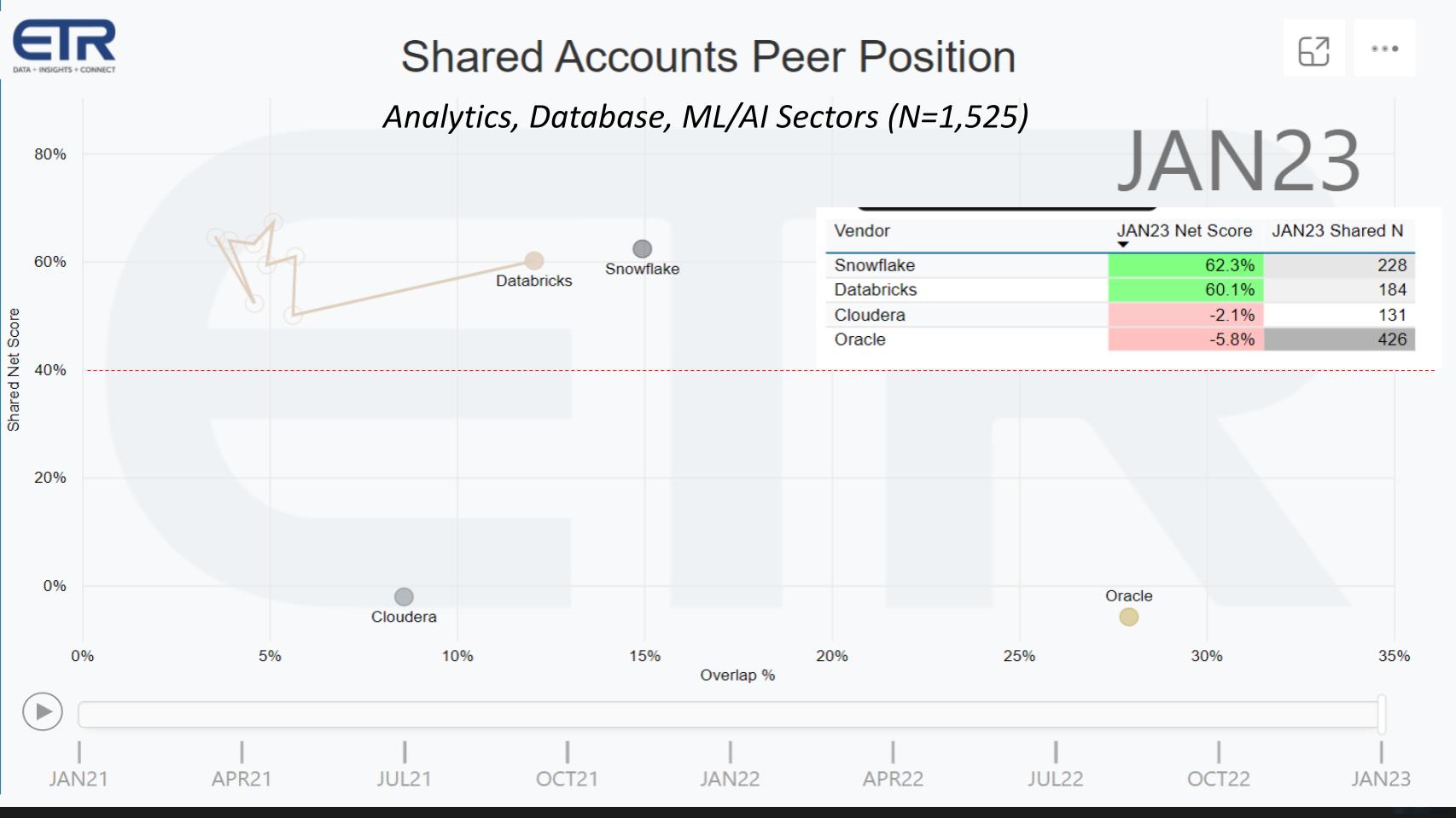
The chart above is from ETR’s quarterly Know-how Spending Intentions Survey. It exhibits Web Rating on the vertical axis, which is a measure of spending momentum. On the horizontal axis is pervasiveness within the knowledge set which is proxy for market presence. The desk insert informs how the dots are plotted – Web Rating towards Shared N. The purple dotted line at 40% signifies a extremely elevated Web Rating. Right here we evaluate Databricks with Snowflake Inc., Cloudera Inc. and Oracle Corp. The squiggly line resulting in Databricks exhibits their path since 2021 by quarter and you may see it’s performing extraordinarily nicely… sustaining an elevated Web Rating, now similar to that of Snowflake, and persistently transferring to the precise.
Why did we select to indicate Cloudera and Oracle? The reason being that Cloudera acquired the entire big-data period began and was disrupted by Spark and Databricks, and naturally the cloud. Oracle in some ways was the goal of early big-data gamers corresponding to Cloudera. Right here’s what former Cloudera Chief Govt Mike Olson mentioned in 2010 on theCUBE, describing “the previous method” of managing knowledge:
Again within the day, in case you had a knowledge drawback, in case you wanted to run enterprise analytics, you wrote the most important verify you possibly can to Solar Microsystems, and you got an amazing massive, single field, central server. And any cash that was left over, you handed to Oracle for a database licenses and also you put in that database on that field, and that was the place you went for knowledge. That was your temple of data.
Listen to Mike Olson explain how data problems were solved pre-Hadoop.
As Olson implies, the monolithic mannequin was too costly and rigid and Cloudera got down to repair that. However the best-laid plans, as they are saying….
We requested George Gilbert to touch upon the success of Databricks and the way it has achieved success. He summarized as follows:
The place Databricks actually got here up Cloudera’s tailpipe was they took big-data processing, made it coherent, made it a managed service so it may run within the cloud. So it relieved prospects of the operational burden. The place Databricks is basically robust is the predictive and prescriptive analytics house: constructing and coaching and serving machine studying fashions. They’ve tried to maneuver into conventional enterprise intelligence, the extra conventional descriptive and diagnostic analytics, however they’re much less mature there. So what which means is, the rationale you see Databricks and Snowflake sort of side-by-side, is there are lots of, many accounts which have each Snowflake for enterprise intelligence and Databricks for AI machine studying. The place Databricks additionally did very well was in core knowledge engineering, refining the info, the previous ETL course of, which sort of become ELT, the place you loaded into the analytic repository in uncooked type and refined it. And so individuals have actually used each, and every is attempting to get into the opposite’s area.
Buyer views on Databricks
The final little bit of ETR proof we wish to share comes from ETR’s roundtables (known as Insights) run by Erik Bradley together with former Gartner analyst Daren Brabham.

Above we present some direct quotes of IT professionals, together with a knowledge science head and a chief data officer. We’ll simply make a couple of callouts – on the high — like all of us, we are able to’t discuss Databricks with out mentioning Snowflake as these two get us all excited. The second remark zeroes in on the flexibleness and the robustness of Databricks from a knowledge warehouse perspective; presumably the person is talking about Photon, basically Databricks’ enterprise intelligence knowledge warehouse. And the final level made is that regardless of competitors from cloud gamers, Databricks has reinvented itself a few instances over time.
We imagine it could be within the strategy of doing so once more. Based on Gilbert:
Their [Databricks’] massive alternative and the large problem, for each tech firm, it’s managing a expertise transition. The transition that we’re speaking about is one thing that’s been effervescent up, but it surely’s actually epochal. First time in 60 years, we’re transferring from an application-centric view of the world to a data-centric view, as a result of selections have gotten extra vital than automating processes.
Transferring from an application-centric to a data-centric world
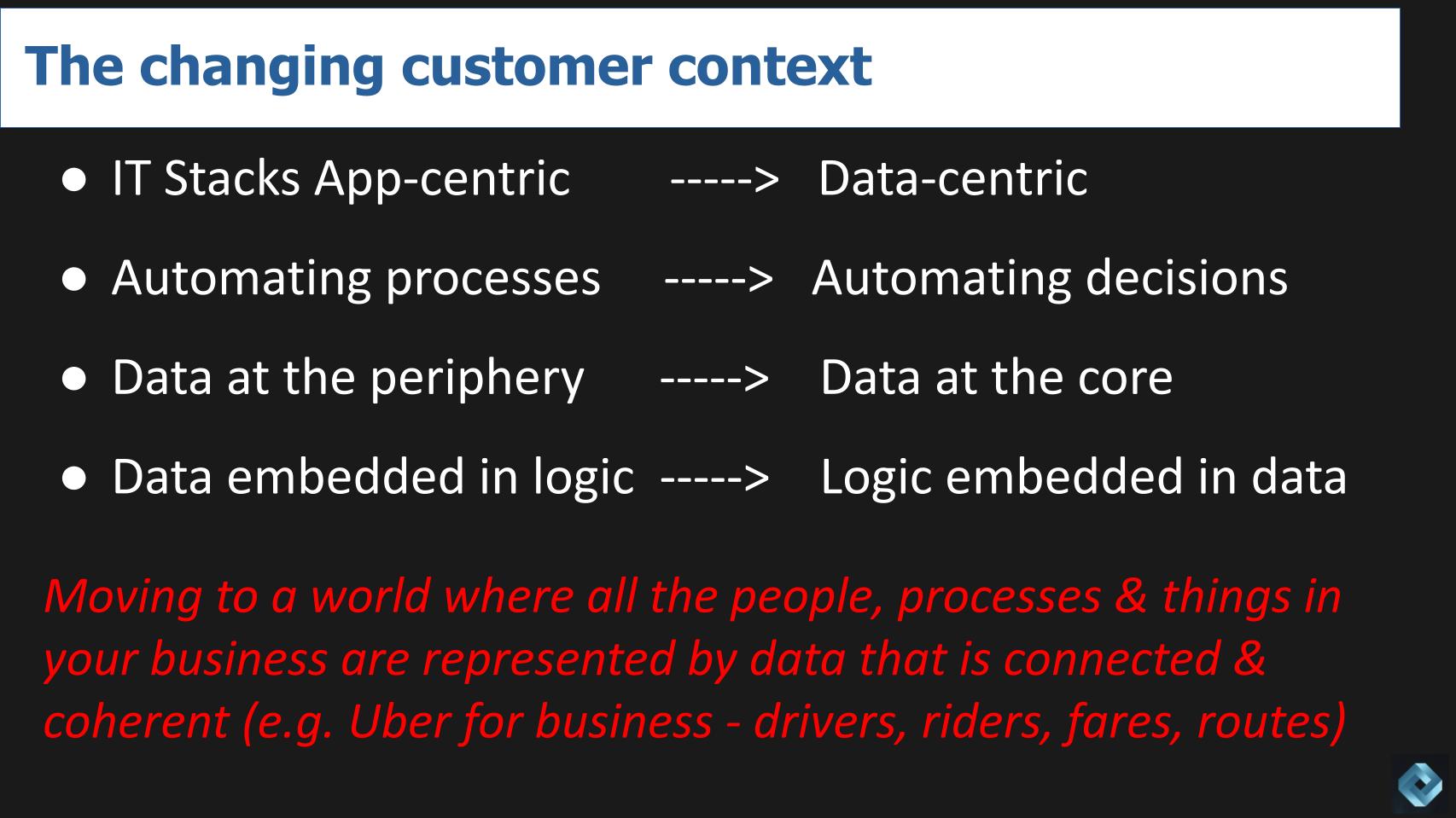
Above we share some bullets on the altering buyer setting the place IT stacks are shifting from application-centric silos to data-centric stacks the place the precedence is shifting from automating processes to automating selections. Knowledge has traditionally been on the outskirts in silos, however organizations corresponding to Amazon.com Inc., Uber Applied sciences Inc. and Airbnb Inc. have put knowledge on the core. And logic is more and more being embedded within the knowledge as a substitute of the reverse. In different phrases, immediately the info is locked contained in the apps – which is why individuals have to extract knowledge and cargo it into a knowledge warehouse.
The purpose is we’re placing forth a brand new imaginative and prescient for the way knowledge will likely be used and we’re utilizing an Uber-like instance to underscore the long run state. Gilbert explains as follows:
Hopefully an instance everybody can relate to: The thought is first, you’re automating issues which might be occurring in the actual world and selections that make these issues occur autonomously with out people within the loop on a regular basis. So to make use of the Uber instance in your telephone, you name a automotive, you name a driver. Robotically, the Uber app then seems at what drivers are within the neighborhood, what drivers are free, matches one, calculates an estimated time of arrival to you, calculates a worth, calculates an ETA to your vacation spot after which directs the driving force as soon as they’re there. The purpose of that is that can’t occur in an application-centric world very simply as a result of all these little apps, the drivers, the riders, the routes, the fares, these name on knowledge locked up in many alternative apps, however they’ve to sit down on a layer that makes all of it coherent.
We requested Gilbert to elucidate why, if the Ubers and Airbnbs and Amazons are doing this already, doesn’t this tech platform exist already? Right here’s what he mentioned:
Sure, and the mission of the complete tech business is to construct providers that make it potential to compose and function related platforms and instruments, however with the abilities of mainstream builders in mainstream companies, not the rocket scientists at Uber and Amazon.
What does the ‘fashionable knowledge stack’ appear like immediately?
By means of evaluation, let’s summarize the development that’s propelling immediately’s knowledge stack and has change into a tailwind for the likes of Databricks and Snowflake.

As proven above, the development is towards a standard repository for analytic knowledge. That could be a number of digital warehouses inside a Snowflake account or lakehouses from Databricks or a number of knowledge lakes in numerous public clouds, with knowledge integration providers that permit builders to combine knowledge from a number of sources.
The information is then annotated to have a standard that means. In different phrases, a semantic layer permits purposes to speak to the info components and know that they’ve frequent and coherent that means.
This method has been extremely efficient relative to monolithic approaches. We requested Gilbert to elucidate in additional element the restrictions of the so-called fashionable knowledge stack. Right here’s what he mentioned:
In the present day’s knowledge platforms added immense worth as a result of they related the info that was beforehand locked up in these monolithic apps or on all these totally different microservices. And that helps conventional BI and AI/ML use circumstances. However now we wish to construct apps like Uber or Amazon.com, the place they’ve acquired basically an autonomously operating provide chain and e-commerce app the place people solely care and feed it. However the factor is to determine what to purchase, when to purchase, the place to deploy it, when to ship it… we wanted a semantic layer on high of the info — so the info that’s coming from all these apps, the totally different apps in a method that’s built-in, not simply related, but it surely all means the identical. The problem is everytime you add a brand new layer to a stack to help new purposes, there are implications for the already current layers. For instance, can they help the brand new layer and its use circumstances? So for example, in case you add a semantic layer that embeds app logic with the info relatively than vice versa, which we’ve been speaking about, and that’s been the case for 60 years, then the brand new knowledge layer faces challenges in the best way you handle that knowledge, the best way you analyze that knowledge. It’s not supported by immediately’s instruments.
Listen to George Gilbert explain the limitations of today’s modern data stacks.
Performing complicated joins at scale will change into more and more vital
In the present day’s fashionable knowledge platforms wrestle to do joins at scale. Within the comparatively close to future, we imagine prospects will likely be managing tons of or hundreds or extra knowledge connections. In the present day’s techniques can perhaps deal with six to eight joins in a well timed method, and that’s the basic drawback. Our premise is {that a} new big-data period is coming, and current techniques gained’t have the ability to deal with it with out an overhaul.
Right here’s how Gilbert explains the dilemma:
One mind-set about it’s that although we name them relational databases, once we truly wish to do a number of joins or once we wish to analyze knowledge from a number of totally different tables, we created an entire new business for analytic databases the place you form of munge the info collectively into fewer tables so that you didn’t must do as many joins as a result of the joins are troublesome and gradual. And once you’re going to arbitrarily be a part of hundreds, tons of of hundreds or throughout hundreds of thousands of components, you want a brand new kind of database. Now we have them, they’re known as graph databases, however to question them, you return to the pre-relational period by way of their usability.
Listen to the discussion on complex joins and future data requirements.
What does the long run knowledge platform appear like?
Let’s lay out a imaginative and prescient of the best knowledge platform utilizing the identical Uber-like instance.
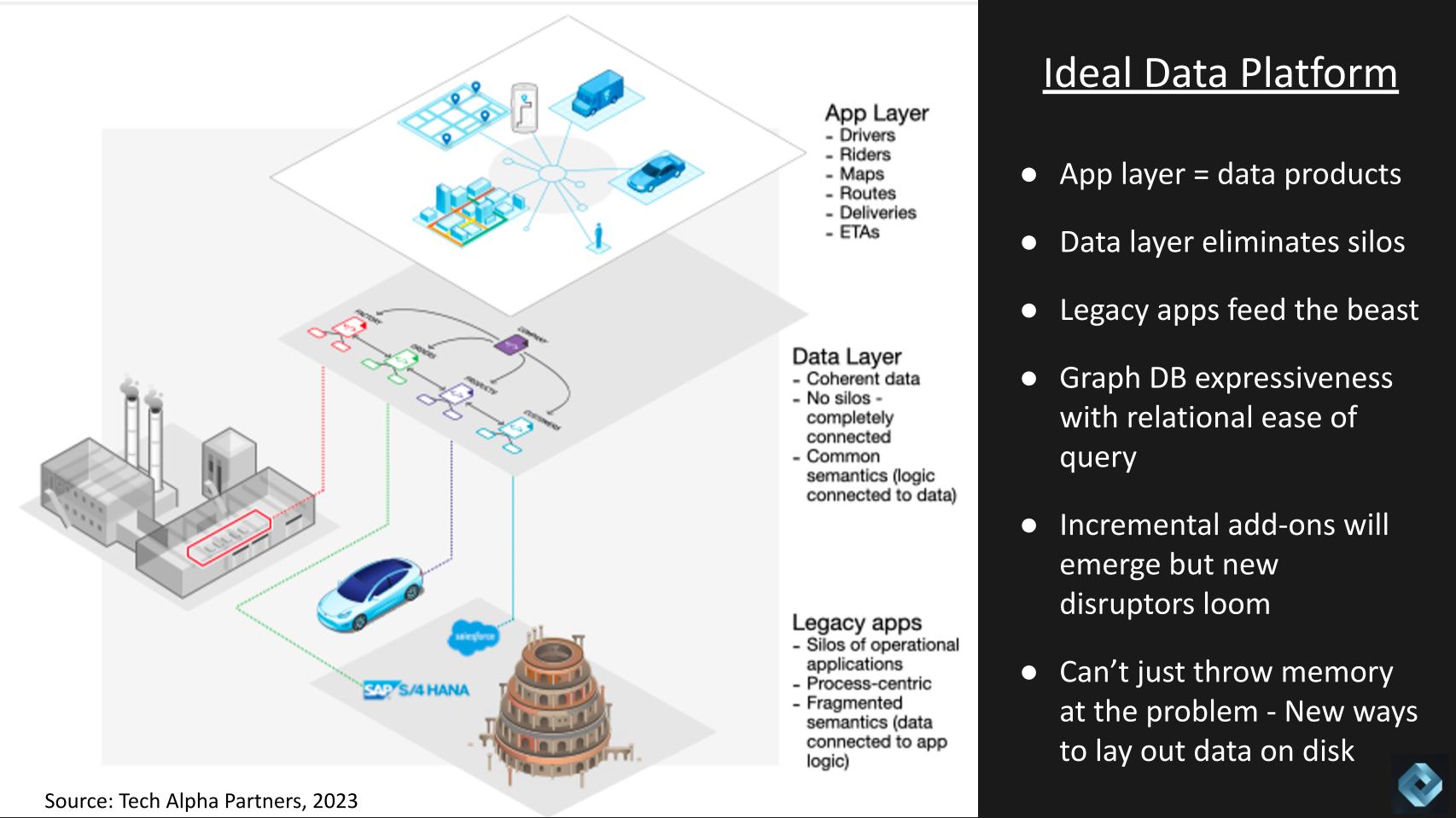
Within the graphic above, we present three layers. The applying layer is the place the info merchandise reside – the instance right here is drivers, riders, maps, routes, and so forth. — the digital model of individuals, locations and issues.
The subsequent airplane exhibits the info layer, which breaks down the silos and connects the info components by semantics. On this layer, all knowledge components are coherent, and on the backside, the operational techniques feed the info layer.
Primarily this structure requires the expressiveness of a graph database with the question simplicity of relational databases.
We requested George Gilbert: Why can’t current platforms simply throw extra reminiscence on the drawback to unravel the issue? He explained as follows:
A few of the graph databases do throw reminiscence on the drawback and perhaps with out naming names, a few of them stay fully in reminiscence. And what you’re coping with is a prerelational in-memory database system the place you navigate between components, and the difficulty with that’s we’ve had SQL for 50 years, so we don’t must navigate, we are able to say what we wish with out the right way to get it. That’s the core of the issue.
Gilbert additional explains:
Graphs are nice as a result of you possibly can describe something with a graph, that’s why they’re turning into so fashionable. Expressive means you possibly can signify something simply. They’re conducive to, you would possibly say, a world the place we now need the metaverse, like with a 3D world, and I don’t imply the Fb metaverse, I imply just like the enterprise metaverse once we wish to seize knowledge about every part, however we wish it in context, we wish to construct a set of digital twins that signify every part occurring on the planet. And Uber is a tiny instance of that. Uber constructed a graph to signify all of the drivers and riders and maps and routes.
However what you want out of a database isn’t only a option to retailer stuff and replace stuff. You want to have the ability to ask questions of it, you want to have the ability to question it. And in case you return to pre-relational days, you needed to know the right way to discover your option to the info. It’s form of like once you give instructions to somebody and so they didn’t have a GPS and a mapping system, you needed to give them flip by flip instructions. Whereas when you’ve got a GPS and a mapping system, which is just like the relational factor, you simply say the place you wish to go, and it spits out the turn-by-turn instructions, which, let’s say, the automotive would possibly comply with or whoever you’re directing would comply with. However the level is, it’s a lot simpler in a relational database to say, “I simply wish to get these outcomes. You determine the right way to get it.” The graph database has not taken over the world as a result of in some methods, it’s taking a 50-year leap backwards.
Mapping Databricks’ choices to the best future state
Now let’s check out how the present Databricks providing maps to that splendid state that we simply laid out. Beneath we put collectively a chart that appears at key components of the Databricks portfolio, the core functionality, the weak spot and the risk which will loom.
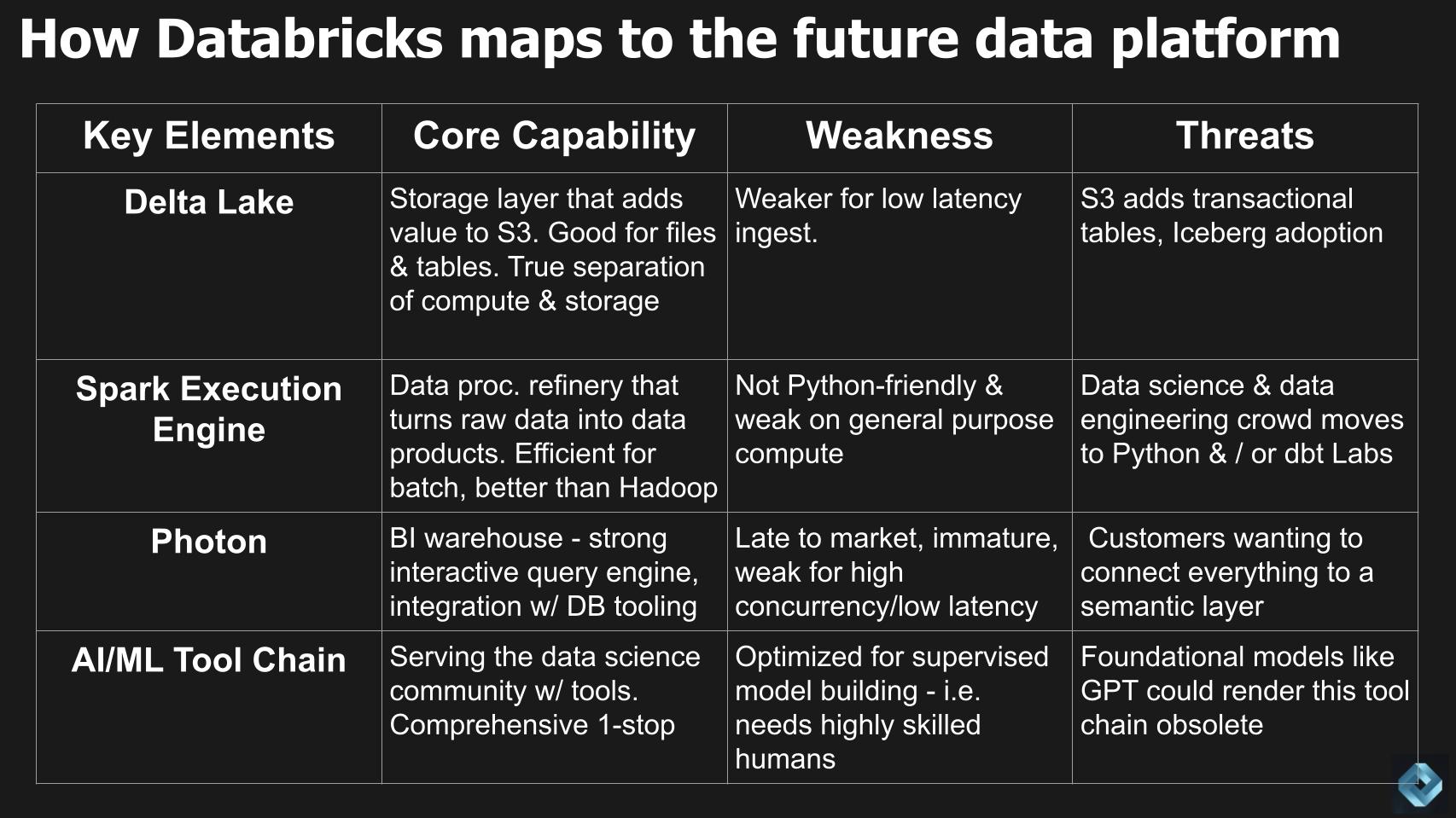
Delta Lake
Delta Lake is the storage layer that’s nice for information and tables. It permits a real separation of compute and storage as unbiased components, but it surely’s weaker for the kind of low-latency ingest we see coming sooner or later. A few of the threats are AWS may add transactional tables to S3 (and/or different cloud distributors to their object shops) and adoption of Iceberg, the open-source desk format, may disrupt.
Gilbert provides further coloration:
That is the basic aggressive forces the place you wish to take a look at what are prospects demanding? What aggressive pressures exist? What are potential substitutes? Even what your suppliers and companions could be pushing. Right here, Delta Lake is, at its core, a set of transactional tables that sit on an object retailer. So consider it in a database system, as that is the storage engine. So since S3 has been getting stronger for 15 years, you possibly can see a state of affairs the place they add transactional tables. Now we have an open-source various in Iceberg, which Snowflake and others help.
However on the identical time, Databricks has constructed an ecosystem out of instruments, their very own and others, that learn and write to Delta tables, that’s what includes the Delta Lake and its ecosystem. In order that they have a catalog, the entire machine studying device chain talks on to the info right here. That was their nice benefit as a result of previously with Snowflake, you needed to pull all the info out of the database earlier than the machine studying instruments may work with it. That was a serious shortcoming. Snowflake has now addressed and glued that. However the level right here is that even earlier than we get to the semantic layer, the core basis is beneath risk.
Listen to George Gilbert’s drilldown into Delta Lake.
The Databricks Spark execution engine
Subsequent we check out the Spark execution engine, which is the info processing refinery that runs actually environment friendly batch processing and disrupted Hadoop. But it surely’s not Python-friendly, and that’s a problem as a result of the info science and knowledge engineering crowd are transferring in that route… in addition to more and more utilizing dbt.
Gilbert elaborates as follows:
As soon as the info lake was in place, what individuals did was they refined their knowledge batch and Spark. Spark has all the time had streaming help and it’s gotten higher. The underlying storage, as we’ve talked about, is a matter. However mainly they took uncooked knowledge, then they refined it into tables that have been like prospects and merchandise and companions. After which they refined that once more into what was like gold artifacts, which could be enterprise intelligence metrics or dashboards, which have been collections of metrics. However they have been operating it on the Spark execution engine, which is a Java-based engine, or it’s operating on a Java-based digital machine, which implies all the info scientists and the info engineers who wish to work with Python are actually working in form of oil and water.
Like in case you get an error in Python, you possibly can’t inform whether or not the issue’s in Python or whether or not it’s in Spark. There’s simply an impedance mismatch between the 2. After which on the identical time, the entire world is now gravitating towards dbt as a result of it’s a really good and easy option to compose these knowledge processing pipelines, and persons are utilizing both SQL in dbt or Python in dbt, and that sort of is an alternative to doing all of it in Spark. So it’s beneath risk even earlier than we get to that semantic layer. It so occurs that dbt itself is turning into the authoring setting for the semantic layer with enterprise clever metrics. However that is the second aspect that’s beneath direct substitution and aggressive risk.
The Photon question engine
Transferring down the desk above, now to Photon: Photon is the Databricks enterprise intelligence warehouse that’s layered on high of its knowledge lake to type its lakehouse structure. Photon has tight integration with the wealthy Databricks tooling. It’s newer and never well-suited for high-currency, low-latency use circumstances that we laid out earlier on this publish.
Gilbert provides further coloration as follows:
There are two points right here. What you have been concerning, which is the high-concurrency, low-latency, when persons are operating like hundreds of dashboards and knowledge is streaming in, that’s an issue as a result of a SQL knowledge warehouse, the question engine, one thing like that matures over 5 to 10 years. It’s certainly one of these items, the joke that [Amazon.com CEO] Andy Jassy makes simply on the whole, he’s actually speaking about Azure, however there’s no compression algorithm for expertise. The Snowflake guys began greater than 5 years earlier, and for a bunch of causes, that lead is just not one thing that Databricks can shrink. They’ll all the time be behind. In order that’s why Snowflake has transactional tables now and we are able to get into that in one other present.
However the important thing level is, near-term, it’s struggling to maintain up with the use circumstances which might be core to enterprise intelligence, which is very concurrent, a number of customers doing interactive queries. However then once you get to a semantic layer, that’s once you want to have the ability to question knowledge that may have hundreds or tens of hundreds or tons of of hundreds of joins. And a SQL question engine, conventional SQL question engine is simply not constructed for that. That’s the core drawback of conventional relational databases.
As a fast apart: We’re not saying that Snowflake is able to deal with all these challenges both. As a result of Snowflake is targeted on knowledge administration and has extra expertise in that area, it could have extra market runway, however lots of the challenges associated to graph databases and the challenges immediately’s fashionable knowledge platforms face round complicated joins apply to Snowflake in addition to Databricks and others.
The Databricks AI/ML device chain
Lastly, coming again to the desk above, we have now the Databricks AI/ML device chain. This has been a aggressive differentiator for Databricks and key functionality for the info science neighborhood. It’s complete, best-of-breed and a one-stop-shop resolution. However the kicker right here is that it’s optimized for supervised mannequin constructing with extremely expert professionals within the loop. The priority is that foundational fashions corresponding to GPT may cannibalize the present Databricks tooling.
We requested Gilbert: Why couldn’t Databricks, like different software program firms, combine basis mannequin capabilities into its platform? Right here’s what he mentioned:
The sound chunk reply to that’s certain, IBM 3270 terminals may name out to a graphical person interface after they’re operating on the XT terminal, however they’re not precisely good residents in that world. The core difficulty is Databricks has this glorious end-to-end device chain for coaching, deploying, monitoring, operating inference on supervised fashions. However the paradigm there’s the shopper builds and trains and deploys every mannequin for every characteristic or utility. In a world of basis fashions that are pre-trained and unsupervised, the complete device chain is totally different.
So it’s not like Databricks can junk every part they’ve completed and begin over with all their engineers. They must preserve sustaining what they’ve completed within the previous world, however they must construct one thing new that’s optimized for the brand new world. It’s a basic expertise transition and their mentality seems to be, “Oh, we’ll help the brand new stuff from our previous stuff.” Which is suboptimal, and as we’ll discuss, their largest patron and the corporate that put them on the map, Microsoft, actually stopped engaged on their previous stuff three years in the past in order that they might construct a brand new device chain optimized for this new world.
Strategic choices for Databricks to capitalize on future knowledge necessities
Let’s shut with what we expect the choices and selections are that Databricks has for its future structure.

Above we lay out three vectors that Databricks is probably going pursuing both independently or in parallel: 1) Re-architect the platform by incrementally adopting new applied sciences. Instance could be to layer a graph question engine on high of its stack; 2) Databricks may license key applied sciences like graph database; 3) Databricks can get more and more aggressive on M&A and purchase relational data graphs, semantic applied sciences, vector database applied sciences and different supporting components for the long run.
Gilbert expands on these choices and addresses the challenges of sustaining market momentum by M&A:
I discover this query probably the most difficult as a result of bear in mind, I was an fairness analysis analyst. I labored for Frank Quattrone, we have been one of many high tech outlets within the banking business, though that is 20 years in the past. However the M&A group was the highest group within the business and everybody needed them on their aspect. And I bear in mind going to conferences with these CEOs, the place Frank and the bankers would say, “You need us on your M&A piece as a result of we are able to do higher.” They usually actually may do higher. However in software program, it’s not like with EMC in {hardware} as a result of with {hardware}, it’s simpler to attach totally different containers.
With software program, the entire level of a software program firm is to combine and architect the parts in order that they match collectively and reinforce one another, and that makes M&A more durable. You are able to do it, but it surely takes a very long time to suit the items collectively. Let me offer you examples. In the event that they put a graph question engine, let’s say one thing like TinkerPop, on high of, I don’t even know if it’s potential, however let’s say they put it on high of Delta Lake, then you’ve got this graph question engine speaking to their storage layer, Delta Lake. However if you wish to do evaluation, you bought to place the info in Photon, which isn’t actually splendid for extremely related knowledge. In the event you license a graph database, then most of your knowledge is within the Delta Lake and the way do you sync it with the graph database?
In the event you do sync it, you’ve acquired knowledge in two locations, which sort of defeats the aim of getting a unified repository. I discover this semantic layer possibility in No. 3 truly extra promising, as a result of that’s one thing you could layer on high of the storage layer that you’ve got already. You simply have to determine then the right way to have your question engines speak to that. What I’m attempting to focus on is, it’s simple as an analyst to say, “You should buy this firm or license that expertise.” However the actually exhausting work is making all of it work collectively and that’s the place the problem is.
A few observations on George Gilbert’s commentary:
- It wasn’t really easy for EMC, the {hardware} firm, to attach all its containers collectively and combine, doubtless as a result of these {hardware} techniques all have totally different working techniques and software program components;
- We’ve seen software program firms evolve and combine. Examples embrace Oracle with an acquisition binge resulting in Fusion – though it took a decade or extra. Microsoft Corp. struggled for years, however its desktop software program monopoly threw off sufficient money for it to lastly re-architect its portfolio round Azure. And VMware Inc. to a big extent has responded to potential substitutes by embracing threats corresponding to containers and increasing its platform through M&A into new domains corresponding to storage, end-user computing, networking and safety;
- That mentioned, these three examples are of corporations that have been established with exceedingly wholesome money flows;
- Databricks ostensibly has a robust stability sheet provided that it has raised a number of billion {dollars} and has vital market momentum. As a non-public firm, it’s troublesome to inform as outsiders but it surely’s doubtless the corporate has inherent profitability and a few knobs to show in a troublesome market whereby it may well protect its money. The argument might be made each methods for Databricks. Which means as a much less mature firm it has much less baggage. Alternatively, as a non-public rising agency, it doesn’t have the sources of a longtime participant like these talked about above.
Key gamers to look at within the subsequent knowledge period
Let’s shut with some gamers to look at within the coming period as cited in No. 4 above. AWS, as we talked about, has choices by extending S3. Microsoft was an early go-to-market channel for Databricks – we truly didn’t deal with that a lot. Google LLC as nicely with its knowledge platform is a participant. Snowflake, after all – we’ll dissect their choices sooner or later. Dbt Labs – the place do they match? And eventually we reference Bob Muglia’s firm, Relational.ai.
Gilbert summarizes his view of those gamers and why they’re ones to look at:
Everyone seems to be attempting to assemble and combine the items that will make constructing knowledge purposes, knowledge merchandise simple. And the crucial half isn’t simply assembling a bunch of items, which is historically what AWS did. It’s a Unix ethos, which is we provide the instruments, you place ’em collectively, since you then have the utmost selection and most energy. So what the hyperscalers are doing is that they’re taking their key worth shops — within the case of AWS it’s DynamoDB, within the case of Azure it’s Cosmos DB — and every is placing a graph question engine on high of these. In order that they have a unified storage and graph database engine, like all the info could be collected in the important thing worth retailer.
Then you’ve got a graph database, that’s how they’re going to be presenting a basis for constructing these knowledge apps. Dbt Labs is placing a semantic layer on high of knowledge lakes and knowledge warehouses and as we’ll discuss, I’m certain sooner or later, that makes it simpler to swap out the underlying knowledge platform or swap in new ones for specialised use circumstances. Snowflake, they’re so robust in knowledge administration and with their transactional tables, what they’re attempting to do is take within the operational knowledge that was once within the province of many state shops like MongoDB and say, “In the event you handle that knowledge with us, it’ll be related to your analytic knowledge with out having to ship it by a pipeline.” And that’s massively priceless.
Relational.ai is the wildcard, as a result of what they’re attempting to do, it’s nearly like a Holy Grail, the place you’re attempting to take the expressiveness of connecting all of your knowledge in a graph however making it as simple to question as you’ve all the time had it in a SQL database, or I ought to say, in a relational database. And in the event that they do this, it’s form of like, it’ll be as simple to program these knowledge apps as a spreadsheet was in comparison with procedural languages, like BASIC or Pascal. That’s the implications of Relational.ai.
Relating to the final level on Relational.ai, we’re speaking about fully rethinking database architectures. Not merely throwing reminiscence on the drawback however relatively rearchitecting databases all the way down to the best way knowledge is laid out on disk. That is why it’s not clear that you possibly can take a knowledge lake or perhaps a Snowflake and simply put a relational data graph on high of these. You might probably combine a graph database, however will probably be compromised as a result of to essentially do what Relational.ai is attempting to do, which is convey the convenience of Relational on high of the ability of graph, you really need to vary the way you’re storing your knowledge on disk and even in reminiscence. So you possibly can’t merely add graph help to a Snowflake, for instance. As a result of in case you did that, you’d have to vary how the info is bodily laid out. And that will break all of the instruments which have been so tightly built-in so far.
How quickly will the following knowledge period be right here and what function does the semantic layer play?
We requested Gilbert to foretell the timeframe by which this disruption would occur. Right here’s what he mentioned:
I feel one thing shocking is happening that’s going to form of come up the tailpipe and take everybody by storm. All of the hype round enterprise intelligence metrics, which is what we used to place in our dashboards the place bookings, billings, income, buyer, these have been the important thing artifacts that used to stay in definitions in your BI instruments, and dbt has mainly created a normal for outlining these in order that they stay in your knowledge pipeline, or they’re outlined of their knowledge pipeline, and executed within the knowledge warehouse or knowledge lake in a shared method, so that every one instruments can use them.
This feels like a digression. It’s not. All these things about knowledge mesh, knowledge cloth, all that’s occurring is we’d like a semantic layer and the enterprise intelligence metrics are defining frequent semantics on your knowledge. And I feel we’re going to seek out by the top of this yr, that metrics are how we annotate all our analytic knowledge to start out including frequent semantics to it. And we’re going to seek out this semantic layer, it’s not three to 5 years off, it’s going to be staring us within the face by the top of this yr.
We stay in a world that’s more and more unpredictable. We’re all caught off-guard by occasions like the highest enterprise capital and startup financial institution in Silicon Valley shutting down. The inventory market is uneven. The Federal Reserve is attempting to be clear however struggles for consistency and we’re seeing severe tech headwinds. Oftentimes these tendencies create circumstances that invite disruption and it seems like this might be a kind of moments the place new gamers and a whole lot of new expertise involves the market to shake issues up.
As all the time, we’ll be right here to report, analyze and collaborate with our neighborhood. What’s your take? Do tell us.
Be in contact
Many thanks George Gilbert for his insights and contributions for this episode. Alex Myerson and Ken Shifman are on manufacturing, podcasts and media workflows for Breaking Evaluation. Particular due to Kristen Martin and Cheryl Knight who assist us preserve our neighborhood knowledgeable and get the phrase out, and to Rob Hof, our editor in chief at SiliconANGLE.
Bear in mind we publish every week on Wikibon and SiliconANGLE. These episodes are all obtainable as podcasts wherever you listen.
Electronic mail [email protected], DM @dvellante on Twitter and touch upon our LinkedIn posts.
Additionally, take a look at this ETR Tutorial we created, which explains the spending methodology in additional element. Word: ETR is a separate firm from Wikibon and SiliconANGLE. If you want to quote or republish any of the corporate’s knowledge, or inquire about its providers, please contact ETR at [email protected].
Right here’s the total video evaluation:
All statements made concerning firms or securities are strictly beliefs, factors of view and opinions held by SiliconANGLE Media, Enterprise Know-how Analysis, different company on theCUBE and visitor writers. Such statements are usually not suggestions by these people to purchase, promote or maintain any safety. The content material introduced doesn’t represent funding recommendation and shouldn’t be used as the idea for any funding choice. You and solely you’re chargeable for your funding selections.
Disclosure: Most of the firms cited in Breaking Evaluation are sponsors of theCUBE and/or purchasers of Wikibon. None of those corporations or different firms has any editorial management over or advance viewing of what’s printed in Breaking Evaluation.