

{kind=link}
![]()

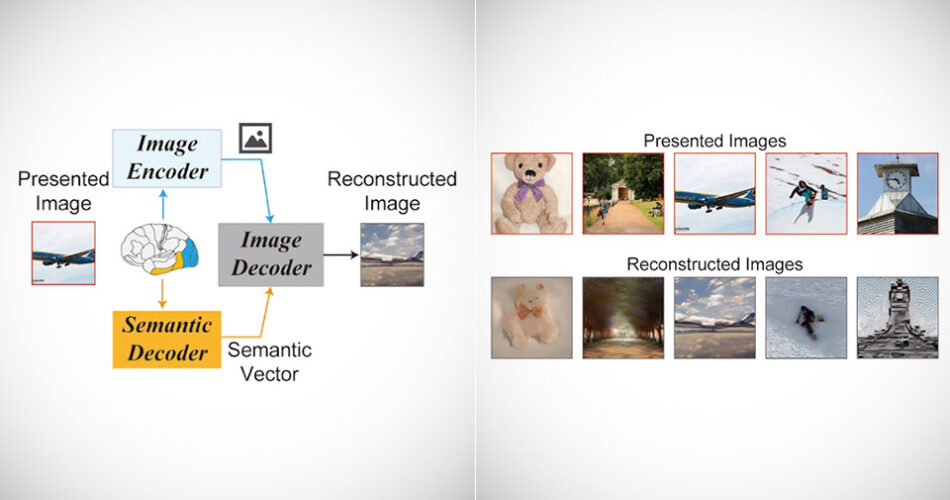
Not like a brain-computer interface, synthetic intelligence will be mixed with human mind exercise to reconstruct high-resolution pictures. How so? Researchers from the Graduate Faculty of Frontier Biosciences at Osaka College used a diffusion mannequin (DM) to decode fMRI knowledge from human brains and reconstruct visible experiences, counting on a latent diffusion mannequin (LDM) that many know as Steady Diffusion.

Coaching or fine-tuning of advanced deep generative fashions is just not required, as this easy framework reconstructs high-resolution pictures from useful Magnetic Resonance Imaging (fMRI) alerts utilizing Steady Diffusion. The text-to-image conversion course of applied by Steady Diffusion incorporates the semantic data expressed by the conditional textual content, whereas concurrently retaining the looks of the unique picture.


We present that our proposed technique can reconstruct high-resolution pictures with excessive constancy in simple vogue, with out the necessity for any extra coaching and fine-tuning of advanced deep-learning fashions. General, our research proposes a promising technique for reconstructing pictures from human mind exercise, and offers a brand new framework for understanding DMs,” mentioned the researchers.
Source link