

{kind=link}
If you happen to run an AI regionally, you get full privateness, no API or subscription prices, offline entry, and also you by no means have to fret about working into your utilization restrict proper if you’re in the course of one thing. For a very long time, AI coding assistants have been janky, unreliable, and painfully sluggish, however newer native fashions can maintain their very own in opposition to the cloud-based fashions so long as you are cautious about how you employ them.
Qwen’s newest coding mannequin launch has been particularly spectacular, and I now use the native mannequin about half the time.
Qwen makes native vibe coding viable
Pair it with VSCodium for a totally open-source expertise
There are a ton of native AI fashions that can allow you to code regionally, and so they ceaselessly leapfrog one another as fashions enhance over time. For probably the most half, I have not discovered these very spectacular—they’re good as very fancy autocompletes, however not a lot else.
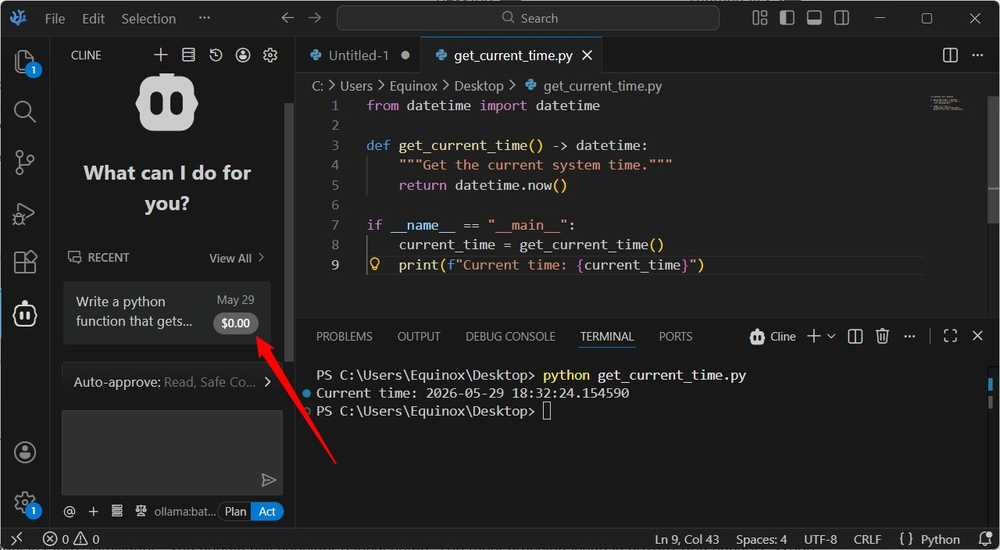
Nevertheless, current fashions make them far more interesting. I have been utilizing a few of Qwen’s coding-specific models, and located they’re lastly ready the place they’re usable on reasonable {hardware} and virtually helpful. It handles code completion, refactoring, and writing exams, and it does it fairly effectively. You should use it to plan or straight write, although I might strongly suggest planning first. It is not practically as good as the large cloud fashions, and it wants the assistance.
I run my local coding models in VSCodium by way of the Cline extension. The complete factor seems as a small sidebar the place you sort your instructions, approve code snippets, and handle your context window. I largely use my native coding AI for easy issues, whereas I go away extra complicated jobs or refactoring to Claude to save lots of tokens.
As a result of your complete setup depends on Ollama, I may make my native AI accessible to any gadget on my residence community. Which means I am not caught seated in entrance of my desktop—I can take my laptop computer
Take into account that AI is consistently evolving. The native LLM area strikes so quick that what’s the gold commonplace as we speak could be outmoded by subsequent month, however even the present choices make the setup well worth the effort.
Cloud fashions are higher, however native is cheap and personal
Privateness, value, and availability add up
Even when a cloud mannequin is extra “clever,” you must nonetheless think about a neighborhood setup. Essentially the most urgent concern is privateness and safety. Once you run a mannequin regionally, your code by no means leaves your machine. If you happen to’re dealing with proprietary firm knowledge or delicate consumer info, that is essential.
Price additionally issues. Claude, ChatGPT, Gemini, and the entire different main gamers cost month-to-month for entry. These plans begin at about $20 per thirty days, however the prices can develop explosively in the event you’re not cautious. A viable native agent means you possibly can cease paying month-to-month subscriptions or worrying about per-token charges.
When you personal the GPU, your solely ongoing value is the electrical energy. It seems like a doubtful worth proposition at first, however think about that Claude Max prices at the very least $100, which is the minimal subscription somebody doing lots of coding will want. After a yr, that’s an RTX 5080. After two years, that’s an RTX 5090 (if you could find one at MSRP).
It is usually good to not depend upon anybody else’s servers. On a couple of event, I’ve gone to make use of Claude or Codex to jot down some code, solely to seek out the servers are briefly down. With your individual native setup, your downtime is usually underneath your management.
Working a coding LLM regionally has some tradeoffs
VRAM, quantization, and context are the true constraints

Working a neighborhood coding LLM is not with out its drawbacks, nonetheless. The massive restrict is {hardware}.
If you happen to’re working a mid-range shopper GPU, just like the 5070 Ti I exploit, you are going to run into bottlenecks. The first constraint is VRAM, which dictates each the scale of the mannequin you possibly can load and the size of the context window you possibly can preserve.
That is the place quantization is available in. You may see phrases like This autumn, Q5, or Q8. That’s principally an indicator of how compressed the mannequin is. Whereas a Q8 (8-bit) mannequin is extra exact, a This autumn (4-bit) mannequin means that you can run a bigger mannequin on {hardware} with much less VRAM with solely a slight lower to output high quality. With the appropriate quantization, I can use some 27B parameter fashions on my 5070Ti, although bigger fashions are out of attain.

What Is an LLM? How AI Holds Conversations
LLMs are an extremely thrilling know-how, however how do they work?
You also needs to count on a pace distinction between native fashions and cloud-based fashions. Native fashions will battle to suit giant, complicated jobs into the context window.
Native coding LLMs are lastly value utilizing
The native LLM choices have lastly crossed the road from a enjoyable novelty to one thing I can really use each day. A giant a part of making these fashions helpful is integration.
It’s best to attempt setting this up as a complement to your cloud instruments by attaching it to VSCodium or the IDE of your alternative. It may not substitute probably the most highly effective fashions for each single process, however having a non-public, free, and always-available assistant by yourself {hardware} is a superb addition to any dev atmosphere.
Source link