

{kind=link}
Cloudflare CEO Matthew Prince introduced yesterday that Google’s search crawler accesses considerably extra web content material than competing AI corporations, creating what the manager characterizes as an unfair aggressive benefit in synthetic intelligence improvement. In keeping with data from the networking infrastructure company, Googlebot efficiently accessed particular person pages virtually two instances greater than ClaudeBot and GPTBot, thrice greater than Meta-ExternalAgent, and greater than thrice greater than Bingbot over a two-month remark interval.
The disclosure coincides with a session opened by the UK’s Competition and Markets Authority examining conduct requirements for Google following its designation with Strategic Market Standing within the search market. Cloudflare launched these findings by each a social media submit from Prince and an in depth weblog submit from coverage executives Maria Palmieri and Sebastian Hufnagel revealed January 30.
We can not have a good marketplace for AI when Google leverages their search monopoly to see 3.2x as a lot of the net as OpenAI, 4.8x as a lot as Microsoft, and greater than 6x as a lot as practically everybody else. Most knowledge wins in AI. Google must play by the identical guidelines as everybody else. https://t.co/5fNYpLtcTY
— Matthew Prince 🌥 (@eastdakota) January 30, 2026
“We can not have a good marketplace for AI when Google leverages their search monopoly to see 3.2x as a lot of the net as OpenAI, 4.8x as a lot as Microsoft, and greater than 6x as a lot as practically everybody else,” Prince wrote in a submit that generated over 354,000 views inside hours. “Most knowledge wins in AI. Google must play by the identical guidelines as everybody else.”
The information reveals stark disparities in content material entry throughout main AI crawlers. Based mostly on sampled distinctive URLs utilizing Cloudflare’s community over two months, Googlebot crawled roughly 8 p.c of noticed pages. In rounded a number of phrases, Googlebot sees 1.70 instances the distinctive URLs accessed by ClaudeBot, 1.76 instances these seen by GPTBot, 2.99 instances Meta-ExternalAgent’s attain, and three.26 instances the pages crawled by Bingbot.
The hole widens dramatically for smaller AI crawlers. In keeping with Cloudflare’s measurements, Googlebot accessed 5.09 instances extra distinctive URLs than Amazonbot, 14.87 instances greater than Applebot, 23.73 instances greater than Bytespider, 166.98 instances greater than PerplexityBot, 714.48 instances greater than CCBot, and 1,801.97 instances greater than archive.org_bot.
These entry differentials stem from publishers’ dependence on Google Seek for site visitors and promoting income. Cloudflare knowledge exhibits that just about no web site explicitly disallows Googlebot in full by robots.txt information, reflecting the crawler’s significance in driving human guests to writer content material. This creates what the CMA describes as a state of affairs the place “publishers haven’t any life like choice however to permit their content material to be crawled for Google’s normal search due to the market energy Google holds usually search.”
The issue extends past easy entry metrics. Google presently operates Googlebot as a dual-purpose crawler that concurrently gathers content material for conventional search indexing and for AI purposes together with AI Overviews and AI Mode. In keeping with the CMA, this implies “Google presently makes use of that content material in each its search generative AI options and in its broader generative AI companies.”
Publishers can not afford to dam Googlebot with out jeopardizing their look in search outcomes, which stay important for site visitors technology and promoting monetization. This dependency forces publishers to simply accept that their content material can be utilized in generative AI applications that return minimal site visitors to their web sites, undermining the enterprise fashions which have sustained digital publishing.
When evaluating crawler blocking patterns by Internet Utility Firewalls, Cloudflare discovered that web sites actively blocking widespread AI crawlers like GPTBot and ClaudeBot outnumbered these blocking Googlebot and Bingbot by practically seven instances between July 2025 and January 2026. Prospects utilizing Cloudflare’s AI Crawl Management reveal clear preferences for sustaining Googlebot entry whereas proscribing different AI crawlers.
The CMA launched its session on proposed conduct necessities for Google on January 28, following the corporate’s October 2025 designation with Strategic Market Standing underneath the Digital Markets, Competitors and Customers Act 2024. The designation encompasses AI Overviews and AI Mode, granting the CMA authority to impose legally enforceable guidelines particularly regarding AI crawling habits with important sanctions for non-compliance.
In keeping with the CMA’s proposed necessities, Google would want to grant publishers “significant and efficient” management over whether or not their content material is used for AI options. The regulator would prohibit Google from taking any motion that negatively impacts the effectiveness of these management choices, reminiscent of deliberately downranking content material in search outcomes.
Cloudflare executives argue the proposed treatments stay inadequate. “The simplest solution to give publishers that essential management is to require Googlebot to be cut up up into separate crawlers,” in accordance with the weblog submit. “That means, publishers might permit crawling for conventional search indexing, which they should appeal to site visitors to their websites, however block entry for undesirable use of their content material in generative AI companies and options.”
The corporate characterizes Google’s dual-purpose crawler as non-compliant with accountable AI bot ideas requiring distinct goal declaration. Not like opponents reminiscent of OpenAI and Anthropic, which function separate crawlers for various features, Google combines multiple purposes by a single bot identifier.
Google maintains practically 20 different specialised crawlers for varied functions together with picture knowledge, video knowledge, and cloud companies. Cloudflare argues this demonstrates the technical feasibility of crawler separation. “Requiring Google to separate up Googlebot by goal — similar to Google already does for its practically 20 different crawlers — just isn’t solely technically possible, but additionally a essential and proportionate treatment,” in accordance with the corporate’s place.
The CMA thought-about crawler separation as an “equally efficient intervention” however finally rejected mandating separation based mostly on Google’s enter characterizing the requirement as overly burdensome. The regulator as an alternative proposed requiring Google to develop new proprietary opt-out mechanisms tied particularly to the Google platform.
Cloudflare acquired suggestions from prospects indicating that Google’s present proprietary opt-out mechanisms, together with Google-Prolonged and ‘nosnippet’, have failed to stop content material utilization in methods publishers can not management. These instruments don’t allow mechanisms for truthful compensation, in accordance with the corporate’s session response.
The proposed conduct necessities would mandate elevated transparency from Google, requiring publication of clear documentation on how crawled content material is used for generative AI and precisely what varied writer controls cowl in follow. Google would want to make sure efficient attribution of writer content material and supply detailed, disaggregated engagement knowledge together with particular metrics for impressions, clicks, and click on high quality.
Nonetheless, Cloudflare characterizes this framework as creating “a state of everlasting dependency” the place publishers should use Google’s proprietary mechanisms underneath situations set by Google slightly than exercising direct, autonomous management. “A framework the place the platform dictates the principles, manages the technical controls, and defines the scope of software doesn’t provide ‘efficient management’ to content material creators or encourage aggressive innovation available in the market,” in accordance with the weblog submit.
The corporate argues that creating new opt-out controls makes it inconceivable for publishers to make use of exterior instruments to dam Googlebot from accessing their content material with out jeopardizing search visibility. Publishers would nonetheless have to permit Googlebot to scrape their web sites, with restricted visibility out there if Google doesn’t respect their signaled preferences and no enforcement mechanisms to deploy independently.
Main publishers have expressed assist for crawler separation necessities. The Each day Mail Group, The Guardian, and the Information Media Affiliation supplied public backing for necessary crawler separation as a treatment, in accordance with Cloudflare’s documentation.
The aggressive implications prolong past writer management. Cloudflare CEO Matthew Prince stated in July 2025 that the corporate would get hold of strategies from Google to dam AI Overviews and Reply Containers whereas preserving conventional search indexing capabilities. “We’ll get Google to supply methods to dam Reply Field and AI Overview, with out blocking traditional search indexing, as nicely,” Prince declared on the time, expressing confidence about securing concessions from the search big.
The timing of Cloudflare’s knowledge launch coincides with mounting regulatory strain on Google’s AI options. Research documented throughout 2025 signifies that AI-driven search summaries scale back writer site visitors by 20-60 p.c on common, with area of interest websites experiencing losses as much as 90 p.c. The Interactive Promoting Bureau Know-how Laboratory shaped its Content material Monetization Protocols working group in August 2025 particularly to handle these challenges.
Google Community promoting income declined 1 p.c to $7.4 billion within the second quarter of 2025, indicating diminished monetization alternatives for AdSense, AdMob, and Google Advert Supervisor individuals as AI options more and more fulfill consumer intent with out requiring web site visits.
The CMA’s designation considers future aggressive dynamics over a five-year horizon. The regulator examined whether or not Microsoft Bing, DuckDuckGo, and different search engines like google and yahoo present ample aggressive strain, discovering that Google’s default agreements throughout main entry factors contribute to sustaining its market place. Knowledge confirmed Google pays billions annually for default search placement.
Cloudflare operates as a significant infrastructure supplier serving thousands and thousands of internet sites globally, positioning the corporate with visibility into crawler habits patterns throughout substantial parts of the web. The networking firm launched pay-per-crawl services in July 2025, permitting content material creators to cost AI crawlers for entry utilizing HTTP 402 Cost Required responses.
The technical implementation particulars matter for web site operators. Robots.txt information permit expression of crawling preferences however depend on voluntary compliance from crawlers. Publishers in search of simpler management can configure Internet Utility Firewalls with particular guidelines to technically stop undesired crawlers from accessing websites no matter bot compliance.
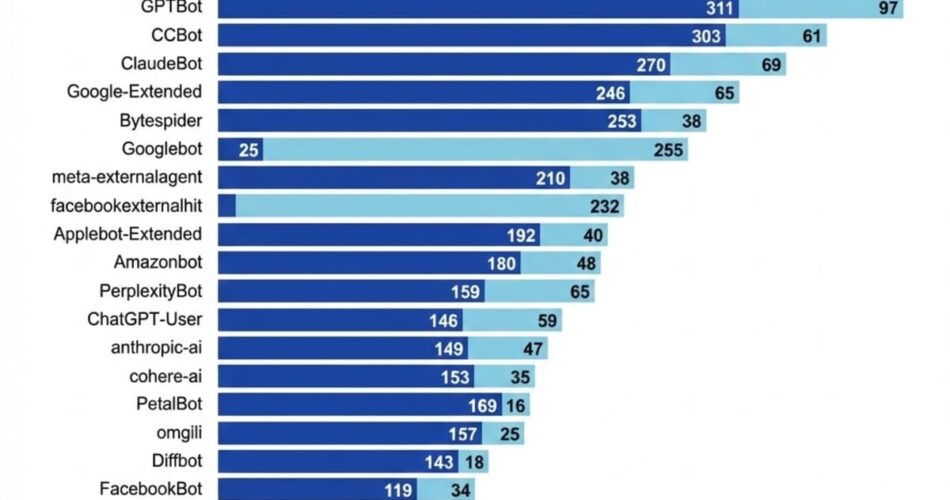
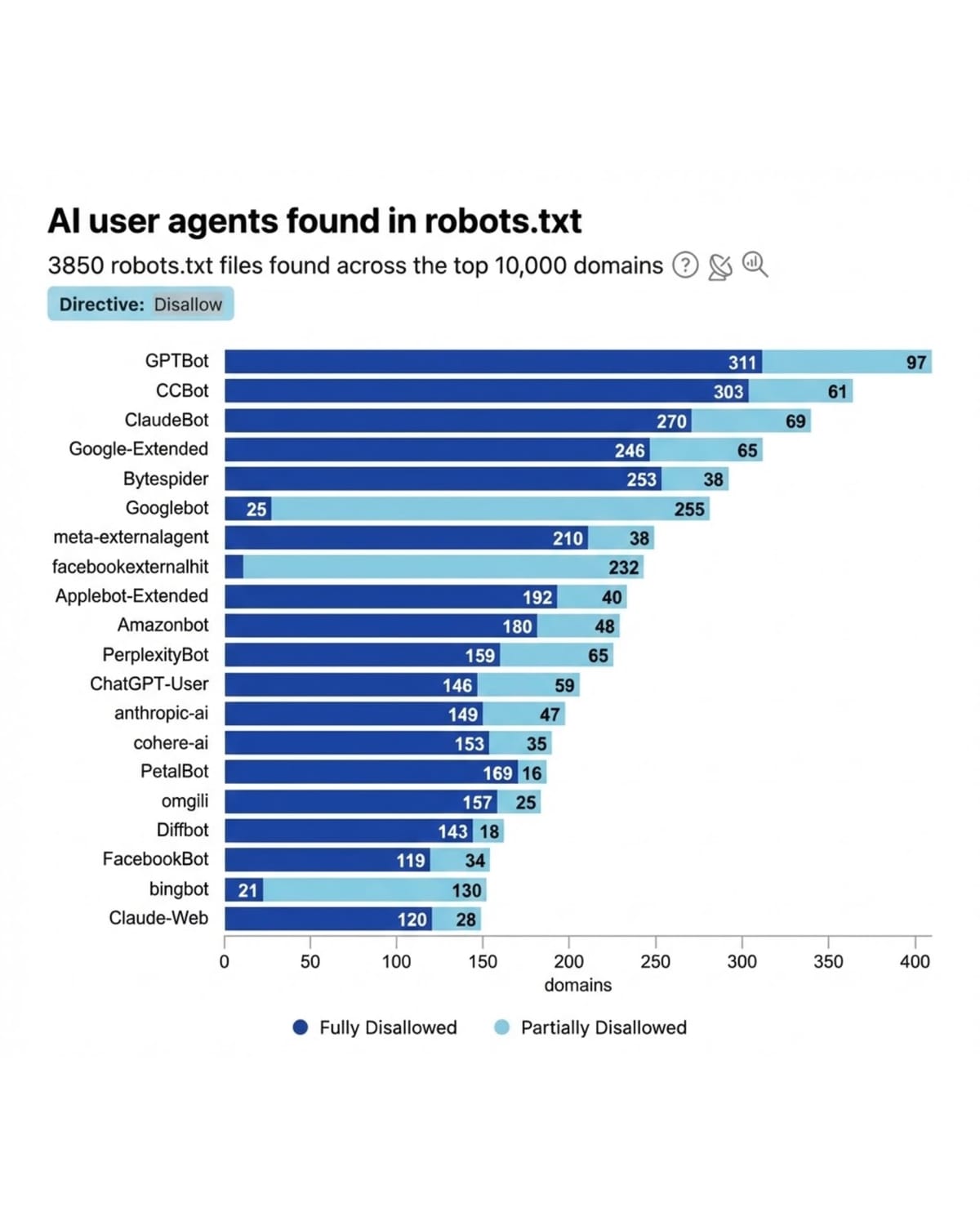
In keeping with Cloudflare evaluation of robots.txt information discovered throughout the highest 10,000 domains, AI consumer brokers present various disallow charges. The information reveals differentiated blocking patterns the place publishers distinguish between crawlers they think about important versus these they view as optionally available or problematic.
The crawler entry disparities documented by Cloudflare validate issues about Google’s aggressive benefits in AI improvement. Not like different AI corporations, Google can use its search crawler to assemble knowledge for a number of AI features with minimal worry that entry can be restricted, in accordance with the CMA evaluation. The regulator acknowledges that this prevents emergence of a well-functioning market the place AI builders negotiate truthful worth for content material.
Different AI corporations face structural disadvantages in a system permitting one dominant participant to bypass compensation completely. Because the CMA states, “[b]y not offering ample management over how this content material is used, Google can restrict the power of publishers to monetise their content material, whereas accessing content material for AI-generated ends in a means that its opponents can not match.”
The session course of permits stakeholders to supply proof and arguments earlier than the CMA imposes remaining conduct necessities. Cloudflare emphasised its dedication to partaking with the CMA and different companions throughout consultations to supply evidence-based knowledge serving to form remaining choices on conduct necessities which are focused, proportional, and efficient.
British regulators keep authority to impose monetary penalties for non-compliance with designated conduct necessities, with potential fines reaching important percentages of annual worldwide group turnover. The Digital Markets, Competitors and Customers Act 2024 grants the CMA expanded powers to instantly decide violations and impose treatments with out court docket proceedings.
The crawler separation debate happens in opposition to broader antitrust enforcement concentrating on Google’s enterprise practices. A Virginia federal court docket dominated in April 2025 that the corporate holds an unlawful monopoly in internet marketing know-how markets. The European Union designated Google as a “gatekeeper” underneath the Digital Markets Act for each search and promoting companies. A U.S. District Courtroom dominated in August 2024 that Google had monopoly energy usually search and search textual content promoting.
Cloudflare’s evaluation extends to enforcement patterns past robots.txt information. The corporate’s AI Crawl Management function, built-in into its Utility Safety suite, exhibits that web sites block different widespread AI crawlers way more continuously than Googlebot and Bingbot. This seven-to-one ratio displays Googlebot’s distinctive place as each an AI crawler and the gateway to go looking visibility.
The networking infrastructure firm argues that necessary crawler separation advantages AI corporations by leveling the enjoying area, along with giving publishers extra management over content material. “Obligatory crawler separation just isn’t a drawback to Google, nor does it undermine funding in AI,” in accordance with Cloudflare’s place. “Quite the opposite, it’s a pro-competitive safeguard that forestalls Google from leveraging its search monopoly to realize an unfair benefit within the AI market.”
Trade observers notice the implications for innovation in AI improvement. If one firm maintains vastly superior entry to web content material by search market dominance, that benefit compounds over time as AI fashions require intensive knowledge for coaching and inference operations. The standard and breadth of coaching knowledge instantly influences mannequin capabilities and aggressive positioning.
The CMA’s session represents the primary deployment of conduct necessities underneath the digital markets competitors regime within the UK. Closing necessities imposed by the regulator turn into legally enforceable guidelines with important sanctions making certain compliance. The method marks a big authorized shift from counting on antitrust investigations to imposing focused interventions when companies maintain substantial, entrenched market energy.
Google’s response to the CMA emphasised the corporate’s contributions to UK companies and shoppers. Oliver Bethell, Google’s Director of Competitors, said that Search helps thousands and thousands of British companies develop and attain prospects in revolutionary methods, in accordance with previous CMA documentation.
The implementation challenges prolong past technical necessities. Enforcement of conduct necessities by the CMA, if accomplished correctly, can be very onerous with out assure that publishers will belief the answer, in accordance with Cloudflare’s evaluation. The corporate argues {that a} framework the place publishers can not stop Google from accessing their knowledge for explicit functions within the first place, however should as an alternative depend on Google-managed workarounds after crawlers have already accessed content material, fails to supply significant management.
Market dynamics assist expectations of eventual cooperation between Google and content material publishers on crawler separation. AI search visitors provide 4.4 times higher value than conventional natural site visitors in accordance with 2025 analysis, creating financial incentives for managed entry slightly than full blocking. This worth differential suggests potential for negotiated options the place publishers keep some entry whereas charging for AI utilization.
The worldwide regulatory panorama exhibits coordination throughout jurisdictions. The European Fee revealed its promoting know-how antitrust determination in opposition to Google in September 2025, imposing a €2.95 billion effective for abusing dominant positions. A number of enforcement actions throughout completely different markets create cumulative strain on Google’s enterprise practices and aggressive positioning.
Cloudflare positioned the UK session as a singular alternative for world management in defending content material worth. “The UK has a singular probability to steer the world in defending the worth of authentic and high-quality content material on the Web,” in accordance with the corporate’s weblog submit. “Nonetheless, we fear that the present proposals fall quick.”
The technical specs matter for publishers evaluating their choices. Crawler separation would allow granular management the place publishers permit conventional search indexing whereas blocking AI coaching and inference purposes. This specificity can’t be achieved by platform-managed opt-out mechanisms that function after crawlers have already accessed content material.
Prince’s social media announcement generated substantial business dialogue, with responses starting from technical implementation inquiries to broader debates about market construction and competitors coverage. Some commenters questioned whether or not crawler blocking would successfully handle aggressive imbalances, whereas others emphasised the significance of clear management mechanisms.
The ultimate CMA determination will set up precedent for the way digital market regulators strategy platform dominance intersecting with rising applied sciences. Whether or not behavioral treatments requiring new opt-out mechanisms show ample, or whether or not structural necessities mandating crawler separation turn into essential, will affect regulatory approaches in different jurisdictions inspecting comparable aggressive issues.
Timeline
- January 14, 2025: CMA launches investigation into Google’s Strategic Market Standing
- July 1, 2025: Cloudflare launches pay-per-crawl service in personal beta
- July 3, 2025: Cloudflare CEO announces plan to acquire Google AI blocking strategies
- August 3, 2024: Research shows 35.7% of top websites now block OpenAI’s GPTBot
- August 20, 2025: IAB Tech Lab launches Content Monetization Protocols working group
- September 16, 2024: Google revamps crawler documentation with product affect info
- September 30, 2025: CMA designates Google with Strategic Market Standing
- November 20, 2025: Google updates crawling infrastructure documentation with technical specs
- January 28, 2026: CMA opens consultation on proposed conduct requirements for Google
- January 30, 2026: Cloudflare publishes blog post and CEO posts data on crawler access disparities
Abstract
Who: Cloudflare CEO Matthew Prince and coverage executives Maria Palmieri and Sebastian Hufnagel launched knowledge affecting Google, OpenAI, Microsoft, Meta, Amazon, Apple, ByteDance, Perplexity, and different AI corporations, alongside publishers globally depending on search site visitors and the UK Competitors and Markets Authority evaluating conduct necessities.
What: Cloudflare knowledge reveals Googlebot accesses 1.70 instances extra distinctive URLs than ClaudeBot, 1.76 instances greater than GPTBot, 2.99 instances greater than Meta-ExternalAgent, and three.26 instances greater than Bingbot over a two-month remark interval, with gaps widening to 166.98 instances greater than PerplexityBot and 714.48 instances greater than CCBot. The corporate argues Google’s dual-purpose crawler combining search indexing and AI purposes creates unfair aggressive benefits requiring necessary crawler separation.
When: Cloudflare revealed findings January 30, 2026, two days after the CMA opened its session on proposed conduct necessities for Google following the corporate’s September 30, 2025 designation with Strategic Market Standing underneath the Digital Markets, Competitors and Customers Act 2024.
The place: The evaluation applies globally throughout Cloudflare’s community serving thousands and thousands of internet sites, with quick regulatory implications for the UK market underneath CMA jurisdiction and potential affect on European Union enforcement underneath the Digital Markets Act and U.S. antitrust proceedings addressing Google’s search and promoting know-how monopolization.
Why: Publishers can not block Googlebot with out shedding search visibility and promoting income, forcing acceptance of content material utilization in AI purposes that return minimal site visitors whereas Google’s opponents face systematic disadvantages accessing coaching and inference knowledge. The aggressive imbalance threatens truthful AI market improvement and writer financial sustainability as AI-driven search summaries scale back conventional site visitors by 20-60 p.c on common in accordance with documented analysis.
Share this text