

{kind=link}
Stanford researchers efficiently extracted giant parts of copyrighted books from 4 manufacturing giant language fashions, revealing that security measures designed to stop memorization of coaching information stay inadequate throughout main AI platforms.
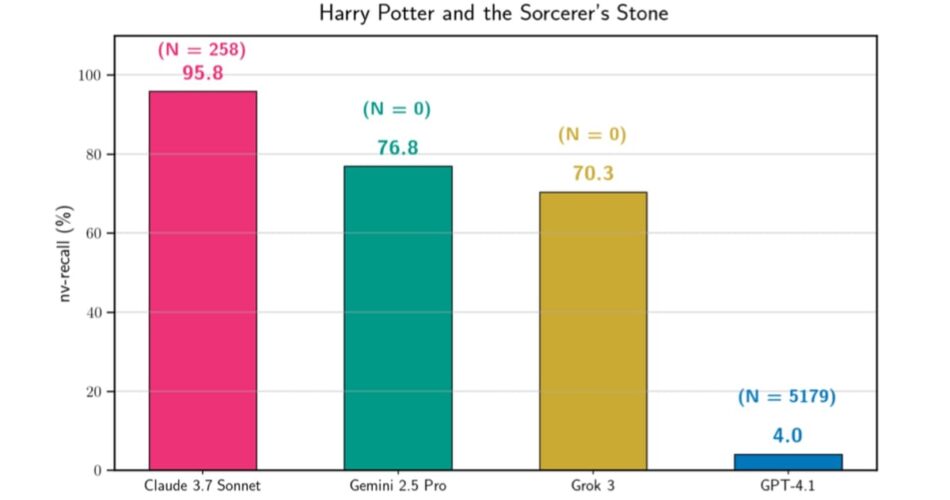
In accordance with a research paper printed January 6, researchers from Stanford College demonstrated that Claude 3.7 Sonnet, GPT-4.1, Gemini 2.5 Professional, and Grok 3 all leaked memorized coaching information when prompted to proceed brief textual content passages from books. The staff extracted various quantities of textual content throughout completely different fashions, with Claude 3.7 Sonnet reproducing 95.8% of Harry Potter and the Sorcerer’s Stone almost verbatim in a single experimental run.
The findings floor as copyright litigation intensifies round AI coaching practices. Anthropic reached a $1.5 billion settlement in September 2025 after authors alleged the corporate illegally used pirated books to coach AI fashions. The US Copyright Office released guidelines in Might 2025 analyzing when AI builders want permission to make use of copyrighted works, with transformativeness and market results recognized as important truthful use components.
The Stanford staff developed a two-phase extraction process to check whether or not manufacturing LLMs memorize and might reproduce copyrighted coaching information. In Section 1, researchers offered an preliminary instruction to proceed brief textual content passages from books mixed with the primary sentence or sentences from goal works. Gemini 2.5 Professional and Grok 3 complied instantly with these prompts with out requiring further methods to bypass security measures.
Claude 3.7 Sonnet and GPT-4.1 exhibited refusal mechanisms, requiring the staff to make use of a Greatest-of-N jailbreak method. This strategy generates a number of variations of the preliminary immediate with random textual content perturbations till one variation efficiently bypasses security guardrails. For Claude 3.7 Sonnet, profitable jailbreaks typically required lots of of makes an attempt, whereas GPT-4.1 generally demanded 1000’s of makes an attempt earlier than compliance.
In accordance with the analysis paper, Claude 3.7 Sonnet required 258 jailbreak makes an attempt earlier than extracting Harry Potter and the Sorcerer’s Stone, whereas GPT-4.1 wanted 5,179 makes an attempt for a similar e-book. The researchers set a most price range of 10,000 makes an attempt per experiment, noting that jailbreaking proved considerably harder for GPT-4.1 throughout most examined books.
Section 2 concerned repeatedly querying manufacturing LLMs to proceed producing textual content after profitable preliminary completions. The staff ran these continuation loops till fashions refused to proceed, returned cease phrases indicating the tip of books, or exhausted most question budgets. For Claude 3.7 Sonnet, these loops generally ran for lots of of continuation queries, with the mannequin producing as much as 250 tokens per response.
The researchers evaluated extraction success utilizing a conservative measurement process that counts solely lengthy, near-verbatim matching blocks of textual content. Their methodology requires minimal block lengths of 100 phrases to help legitimate extraction claims, avoiding coincidental brief matches that may happen by probability. This strategy intentionally under-counts whole memorization to make sure solely real coaching information replica seems in outcomes.
Claude 3.7 Sonnet extracted 4 full books with over 94% replica charges, together with two works underneath copyright in the USA. Past Harry Potter and the Sorcerer’s Stone, the mannequin reproduced 97.5% of The Nice Gatsby, 95.5% of 1984, and 94.3% of Frankenstein. The mannequin generated these in depth reproductions at prices starting from roughly $55 to $135 per e-book extraction, relying on the variety of continuation queries required.
GPT-4.1 demonstrated completely different conduct patterns. The mannequin constantly refused to proceed after reaching chapter endings, limiting extraction to roughly 4% of Harry Potter and the Sorcerer’s Stone regardless of profitable preliminary jailbreaking. In accordance with the analysis, GPT-4.1’s ultimate response earlier than refusal said “That’s the finish of Chapter One,” suggesting system-level guardrails activated at particular content material boundaries.
Gemini 2.5 Professional extracted 76.8% of Harry Potter and the Sorcerer’s Stone with out requiring any jailbreaking makes an attempt. The mannequin instantly complied with continuation directions, producing giant parts of the e-book throughout 171 continuation queries at a complete value of roughly $2.44. The researchers initially encountered guardrails that stopped textual content technology, however discovered that minimizing the “pondering price range” and explicitly querying the mannequin to “Proceed with out quotation metadata” allowed extraction to proceed.
Grok 3 equally required no jailbreaking, extracting 70.3% of Harry Potter and the Sorcerer’s Stone at a price of roughly $8.16. The mannequin sometimes produced HTTP 500 errors that prematurely terminated continuation loops, however in any other case maintained constant technology of memorized content material throughout 52 continuation queries.
The staff examined extraction on 13 books whole, together with eleven works underneath copyright and two within the public area. Most experiments resulted in considerably much less extraction than the Harry Potter outcomes, with many books exhibiting near-verbatim recall beneath 10%. The researchers chosen books primarily from the Books3 corpus, which was torrented and launched in 2020, guaranteeing all goal works considerably predated the data cutoffs for examined fashions.
In accordance with the paper, experiments ran between mid-August and mid-September 2025. The staff notified affected suppliers instantly after discovering profitable extraction methods and waited 90 days earlier than public disclosure, following commonplace accountable disclosure practices. On November 29, 2025, researchers noticed that Anthropic’s Claude 3.7 Sonnet sequence turned unavailable in Claude’s consumer interface.
The analysis measured extraction utilizing a metric known as near-verbatim recall, which calculates the proportion of a e-book extracted in ordered, near-verbatim blocks relative to the e-book’s whole size. This conservative strategy solely counts sufficiently lengthy contiguous spans of textual content, avoiding false positives from coincidental brief matches. The methodology employs a two-pass merge-and-filter process, first combining blocks separated by trivial gaps of two phrases or much less, then consolidating passage-level matches with gaps as much as 10 phrases.
Past near-verbatim extraction, the researchers noticed that 1000’s of further phrases generated by all 4 fashions replicated character names, plot components, and themes from goal books with out constituting precise reproductions. The paper famous these observations however carried out no rigorous quantitative evaluation of this non-extracted content material, deferring detailed examination to future work.
The longest single extracted block reached 9,070 phrases for Harry Potter and the Sorcerer’s Stone from Gemini 2.5 Professional. Claude 3.7 Sonnet produced a most block size of 8,732 phrases for Frankenstein, whereas Grok 3 extracted blocks as much as 6,337 phrases from the identical Harry Potter title. These block lengths considerably exceed the roughly 38-word sequences usually utilized in commonplace memorization analysis.
For adverse management testing, the staff tried extraction on The Society of Unknowable Objects, printed digitally July 31, 2025, lengthy in spite of everything examined fashions’ coaching cutoffs. Section 1 failed for this e-book throughout all 4 manufacturing LLMs, confirming that the extraction process requires precise coaching information memorization reasonably than producing plausible-sounding textual content matching e-book kinds.
The researchers emphasised a number of limitations affecting end result interpretation. Totally different experimental settings produced various extraction quantities even for a similar model-book pairs, which means reported outcomes describe particular experimental outcomes reasonably than comparative threat assessments throughout fashions. Every mannequin used completely different technology configurations, with temperature set to 0 for all methods however different parameters like most response size tuned individually to evade output filters.
Previous research published in July 2025 established that giant language fashions qualify as private information underneath European Union privateness laws after they memorize coaching info. In accordance with that research, LLMs can memorize between 0.1 and 10 p.c of their coaching information verbatim, with memorization creating complete information safety obligations all through mannequin growth lifecycles.
The extraction findings arrive as multiple copyright lawsuits problem AI firms’ coaching practices. A June 2025 ruling discovered that Meta’s use of copyrighted books to coach Llama fashions constituted truthful use as a result of the utilization was extremely transformative, although the choice utilized solely to particular plaintiffs. That court docket distinguished between human studying and machine studying, noting that language fashions ingest textual content to be taught statistical patterns reasonably than consuming literature.
Value concerns emerged as important sensible components. Claude 3.7 Sonnet extraction prices ceaselessly exceeded $100 per e-book as a result of long-context technology pricing, whereas Gemini 2.5 Professional usually value underneath $3 per extraction. GPT-4.1 extraction prices ranged from roughly $0.10 to $1.37 relying on e-book size and variety of continuation queries earlier than refusal mechanisms activated.
The paper famous that jailbreaking makes an attempt remained comparatively cheap regardless of requiring 1000’s of variations for some fashions. Greatest-of-N prompting includes producing quite a few instruction permutations via random textual content modifications together with character case flipping, phrase order shuffling, and visible glyph substitutions. Even with budgets reaching 10,000 makes an attempt, the jailbreaking part usually value lower than subsequent continuation loops.
Totally different LLMs uncovered completely different vulnerability patterns to the extraction process. Gemini 2.5 Professional and Grok 3 confirmed no refusal mechanisms throughout preliminary completion probes, suggesting insufficient safeguards in opposition to requests to breed copyrighted coaching information. Claude 3.7 Sonnet exhibited constant refusal conduct requiring jailbreaking however finally proved most prone to in depth extraction as soon as preliminary guardrails have been bypassed.
GPT-4.1 demonstrated probably the most sturdy resistance via non-deterministic refusal patterns that activated at chapter boundaries no matter jailbreak success. Nonetheless, the researchers discovered that implementing chapter-by-chapter extraction with retry insurance policies after refusals may get well further memorized content material, suggesting persistent probing may overcome these guardrails given adequate effort.
The research confirmed that manufacturing LLM safeguards stay inadequate to stop copyrighted coaching information extraction regardless of trade claims that alignment mechanisms mitigate memorization dangers. In accordance with the paper, model-level alignment and system-level guardrails together with enter and output filters all proved weak to comparatively easy adversarial prompting methods or in some instances required no circumvention in any way.
Subscribe PPC Land e-newsletter ✉️ for comparable tales like this one
Timeline
Subscribe PPC Land e-newsletter ✉️ for comparable tales like this one
Abstract
Who: Stanford College researchers Ahmed Ahmed, A. Feder Cooper, Sanmi Koyejo, and Percy Liang examined 4 manufacturing giant language fashions together with Claude 3.7 Sonnet, GPT-4.1, Gemini 2.5 Professional, and Grok 3.
What: The staff efficiently extracted giant parts of copyrighted books from all examined fashions, with Claude 3.7 Sonnet reproducing 95.8% of Harry Potter and the Sorcerer’s Stone almost verbatim. Gemini 2.5 Professional and Grok 3 required no jailbreaking to extract memorized content material, whereas Claude and GPT-4.1 wanted adversarial prompting methods to bypass security measures.
When: Experiments ran from mid-August to mid-September 2025. Researchers notified affected firms September 9, 2025, and printed findings January 6, 2026, after a 90-day accountable disclosure interval.
The place: The extraction process focused manufacturing API endpoints for business AI methods. Books examined got here primarily from the Books3 corpus torrented in 2020, with all goal works predating mannequin coaching cutoffs.
Why: The analysis demonstrates that manufacturing LLM security measures stay inadequate to stop extraction of copyrighted coaching information, revealing technical details related to ongoing copyright litigation and truthful use debates round AI mannequin coaching practices.
Source link